Чому розробити власну IT/OT інфраструктуру складніше, ніж ви думаєте - 10 підводних каменів і як їх уникнути
Оригінальна стаття Why designing your own IT / OT infrastructure is harder than you might think - 10 Pitfalls and how to avoid them
Навігація в дизайні IT/OT інфраструктури без MQTT, Kafka та Kubernetes? Ми теж вирушили на цей шлях і зіткнулися з численними викликами. Ми сподіваємося, що наш досвід допоможе вам знайти кращі рішення.
Ця публікація в блозі була вперше представлена на конференції Building IoT 2023 у Мюнхені, Німеччина, під назвою «Інструменти та методи обробки масштабованих даних у промисловому Інтернеті речей». Відтоді його було переписано для публікації як статтю в блозі. Ви можете переглянути оригінальне оголошення тут.
Розробка ефективної ІТ/ОТ-інфраструктури може бути важким завданням, враховуючи її складність і безліч залучених сервісів і інструментів. Протягом останніх шести років ми, команда UMH Systems, наважувалися пройти крізь цей лабіринт, у пошуках розробки надійної еталонної архітектури. Шляхом проб і помилок, читаючи статті і навчальні посібники ми отримали безцінні уроки як з нашого досвіду, так і з досвіду лідерів галузі.
І не лише ми говоримо про зміни ІТ та ОТ інфраструктури:
- Існує концепція стеку MING, що складається з Mosquitto, InfluxDB, Node-RED і Grafana.
- Комбінація MQTT і Kafka настільки популярна, що HiveMQ не лише пише багато статей у блозі про це, але Kafka Connector HiveMQ також є найбільш продаваним корпоративним плагіном.
- Хлопці з Kafka багато пишуть про IT та OT, наприклад, у блозі Kai Waehners.
- Марк Джекль і Себастьян Верле з MaibornWolff створили свою архітектуру «One Size Fits All» для промислових платформ IoT (рис.1).
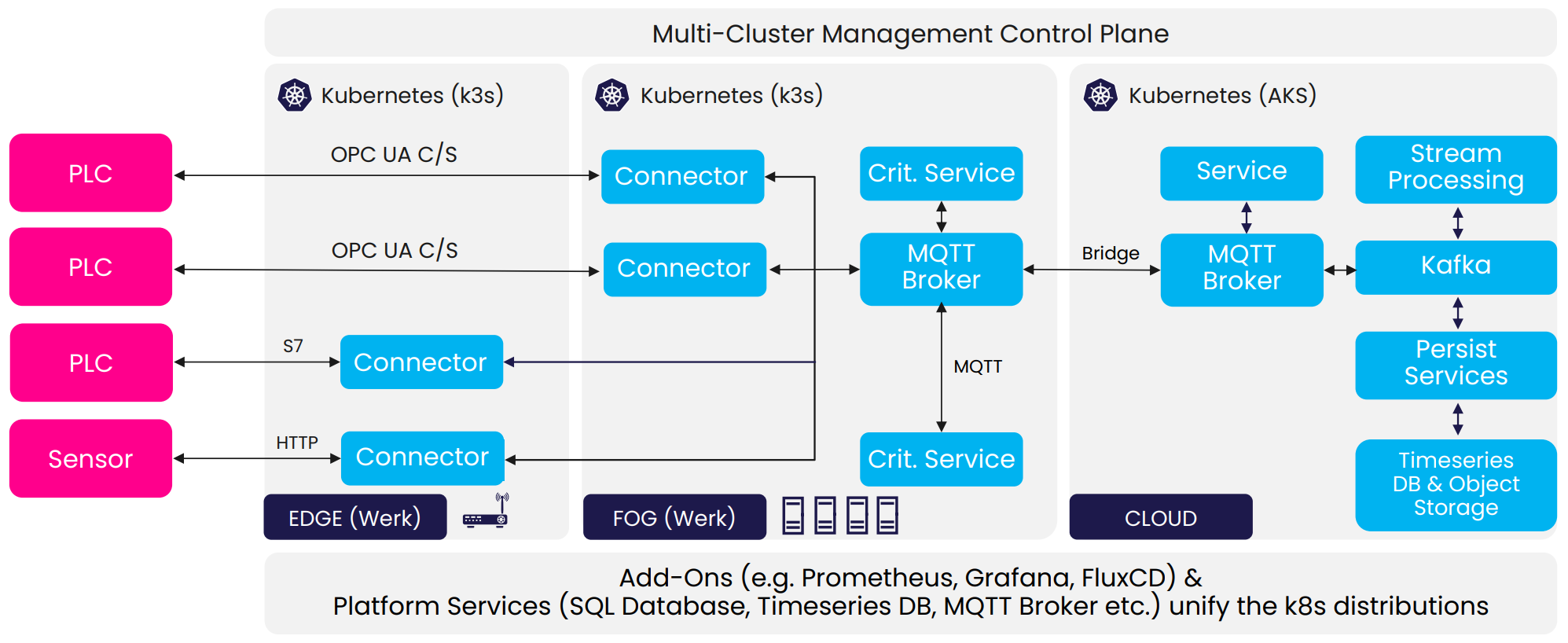
рис. 1. MaibornWolff Еталонна архітектура з виступу «Одна розмірна архітектура для всіх» для платформ IIoT від Марка Себастьяна
До речі: згадані далі еталонні архітектури здебільшого вбудовано в United Manufacturing Hub, який ви можете налаштувати, використовувати та керувати ним протягом 20 хвилин. Подивіться тут!
Але чому створення ІТ/ОТ-інфраструктури є таким складним завданням, яке включає таку кількість різноманітних служб та утиліти? Навіщо використовувати не тільки MQTT, але й комбінацію MQTT і Kafka? І навіщо докладати зусиль, щоб використовувати Kubernetes і Helm Chart замість Docker Compose? Чому я повинен інвестувати в дорогі датчики та апаратне забезпечення OT замість дешевших альтернатив? Нам довелося важким шляхом з’ясувати, чому це набагато складніше, якщо не використовувати ці архітектури та утиліти.
Ця стаття має на меті пролити світло на проблеми, пов’язані з розробкою ІТ/ОТ-інфраструктури, розгадати причини вибору певних утиліт і сервісів і поділитися важко-пройденими уроками, засвоєними з нашої подорожі. Ми сподіваємося, що допоможемо вам уникнути помилок, які ми зробили, і знайти ефективні рішення.
2016-2017: Проблеми рішень Low-Code/No-Code
У 2016–2017 роках я, Джеремі Теохаріс (тепер технічний директор і співзасновник), відповідав за інтеграцію різних рішень індустрії 4.0 у модельний завод у Центрі цифрових можливостей Ахена. Цей модельний завод мав на меті продемонструвати якомога більше рішень. Однак я зіткнувся зі значними труднощами під час об’єднання та масштабування цих рішень, які ґрунтувалися на відмінностях між інформаційними технологіями (ІТ) і операційними технологіями (ОТ).

рис.2.
Підводний камінь 1: однакова обробка для ІТ і ОТ
Щоб досягти бажаної інтеграції рішень industrie 4.0, мені довелося об’єднати кілька різних інструментів від IT та OT. Спочатку я припускав, що поєднання обох буде простим, враховуючи їх передбачувану схожість, але я помилявся.
Інформаційні технології (ІТ) та операційні технології (ОТ) — це дві різні сфери, які, здається, існують у різних світах, якщо придивитися ближче. IT займається мережами, серверами, віртуальними машинами та мовами програмування, такими як C, C++, Java, Python або Golang. У сфері ІТ такі аспекти, як швидкі цикли розробки (наприклад, гнучка розробка програмного забезпечення, безперервна інтеграція та доставка), масштабованість і користувацький досвід є дуже важливими, тоді як надійність, безпека, стандарти та сертифікація менш важливі. Це пояснюється тим, що ІТ-системи часто мають резервування обладнання та високодоступне програмне забезпечення, а наслідки апаратних збоїв зазвичай менші.
З іншого боку, OT зосереджується на програмуванні ПЛК, унікальних мовах програмування та протоколах, електроніці та повільніших темпах змін. Домен OT приділяє велике значення надійності, безпеці, стандартам і сертифікаціям через потенціал надзвичайної шкоди майну та, що найважливіше, людям, тривалий термін служби машин (20-30 років, іноді 50+ років) і законодавчі вимоги для безпеки та надійності. Такі аспекти, як взаємодія з користувачем, швидкі цикли розробки та ІТ-безпека, менш важливі в домені OT.
Ця фундаментальна відмінність між ІТ та ОТ ускладнила пошук способу інтеграції, поєднання та масштабування різних рішень у існуючі машини та системи. Візьмемо, наприклад, додавання підключення Інтернету до машини. Зазвичай мережеві кабелі для цього відсутні. ІТ-спеціалісти очікують використання цих кабелів, але OT не несе відповідальності за їх встановлення, завдання, яке зазвичай доручають спеціалізованим електрикам. Крім того, через стандарти OT додати IT-комутатор до електричної шафи машини непросто. Компоненти OT у шафі встановлені на стандартизованих рейках і підключені до джерела живлення 24 В, специфікаціям, яким ІТ-обладнання часто не відповідає. У той момент, коли в гру вступає програмне забезпечення, ці відмінності майже стали непереборними.
Більше інформації про відмінності між ІТ та ОТ можна знайти в наших вступних курсах: Information Technology та Operational Technology.
Підводний камінь 2: неправильне уявлення про Low-Code
Спочатку я був оптимістично налаштований щодо наявності багатьох інструментів, рекламованих як прості в інтеграції рішення з низьким кодом. Однак ці інструменти часто не відповідали своїм рекламованим можливостям, оскільки вони не були такими зручними для користувача та легкими для інтеграції, як обіцяли. Однією з поширених помилок було те, що низький код означає відсутність коду. Насправді все ще були необхідні складні індивідуальні налаштування, що призвело до багатьох імпровізованих рішень, які вимагали значного обсягу кодування.
Ця залежність від підходів із низьким кодом також ускладнювала дотримання найкращих практик, наприклад використання Git для контролю версій. Ці коригування та обмеження неймовірно ускладнили розгортання, автоматизацію та масштабування багатьох екземплярів. Крім того, перевірені інструменти були не тільки недостатніми та непрактичними, але й дорогими. Зрештою, для адаптації бажаних рішень довелося найняти спеціалізованих ІТ-системних інтеграторів. Незважаючи на їхні зусилля, рішення часто були більш обхідними, ніж належне програмне забезпечення, засноване на найкращих практиках, а висока вартість ліцензій залишалася. Цей досвід виявився дуже неприємним.
Git — це розподілена система контролю версій, яка дозволяє кільком людям працювати над проектом одночасно, не перезаписуючи зміни, внесені один одним. Він відстежує та записує зміни у файлах, дозволяючи користувачам повернутися до будь-якої попередньої версії, якщо це необхідно. Git в основному використовується для розробки програмного забезпечення, але також може використовуватися для будь-яких типів файлів, таких як документи чи зображення. Це особливо корисно в командних проектах, розробці з відкритим кодом і для керування складними проектами з різними версіями та функціями.
2018: Боротьба з проблемами вбудованих систем і обладнання
У 2018 році під час кількох досліджень клієнтів McKinsey я модернізував старе обладнання новими датчиками для розрахунку OEE виробничих ліній.
Підводний камінь 3: недооцінка важливості сертифікатів OT
Я випробував альтернативу моїм попереднім рішенням: недорогі стандартизовані шлюзи на основі вбудованих систем, які спрощували підключення датчиків і доступ до зібраних даних для створення інформаційної панелі чи інших сервісів. Однак це обладнання не було належним обладнанням OT і часто було непридатним для суворих умов виробництва. Наприклад, електромагнітні перешкоди від конвеєрної стрічки вивели з ладу шлюзи в одному розгортанні. Крім того, усунення несправностей без прямого доступу до апаратного забезпечення було майже неможливим через обмеження апаратного забезпечення.
Неоптимально сказати клієнту в Японії відкрутити встановлене обладнання, підключити його до ноутбука спеціальним кабелем і залишити його там сидіти, запустивши TeamViewer, поки лінія безперервно працює.
Уразливості шлюзів і вимоги щодо усунення несправностей звели нанівець їх вартість придбання та переваги встановлення порівняно з традиційними ПЛК.
Підводний камінь 4 (1/2): виклики з підходом, орієнтованим на хмару
У моїх зусиллях щодо вдосконалення я вибрав підхід, який базується на хмарі, надсилаючи всі дані за межі майданчику для подальшої обробки. Інструменти SaaS надали доступні та прості у використанні інформаційні панелі OEE. Однак ці інструменти давали збій, коли справа доходила до налаштування чи інтеграції, оскільки були недоступними або надзвичайно дорогими.
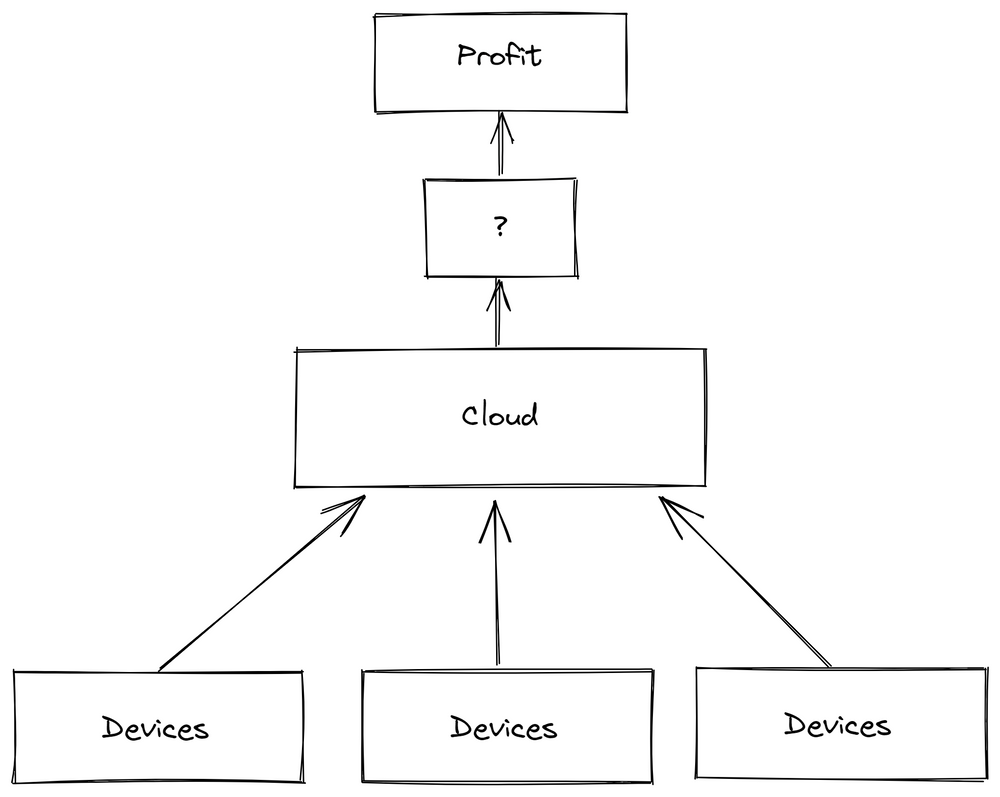 рис.3. 1. Connect everything to the cloud –> 2. ? –> 3. Profit
рис.3. 1. Connect everything to the cloud –> 2. ? –> 3. Profit
Нестабільність мережі та проблеми з доступом на великих підприємствах виявилися серйозними проблемами. В одному випадку виробництво відбувалося кількома поверхами нижче рівня землі, де мобільне з’єднання даних було в кращому випадку ненадійним. Тому мені потрібно було встановити розширювачі стільникових даних, які є безладом з технічної та нормативної сторони.
2019 - Власна компанія, власне обладнання та MQTT
Через розчарування я об’єднав зусилля з двома іншими співробітниками, і ми заснували власну компанію в 2019 році, щоб вирішити проблему з відсутністю простих і легких у розгортанні рішень.
Підводний камінь 5: переоцінка ІТ-компетентності системних інтеграторів OT
Ми створили першу версію нашого FactoryCube, невеликої електричної шафи, побудованої зі стандартизованого апаратного забезпечення OT, такого як ПЛК. Він під’єднався до віртуальної машини Azure у хмарі, де працює Mosquitto, InfluxDB, Telegraf і Grafana, що дозволяє підключати цифрові та аналогові датчики та витягувати дані за допомогою MQTT для подальшого використання.
 рис.4. Перша версія FactoryCube
рис.4. Перша версія FactoryCube
Основною перевагою FactoryCube була його конструкція «підключай і працюй», що полегшувало впровадження на існуючих виробничих лініях. Однак програмування та налаштування програмного забезпечення та сервісів, таких як підключення через MQTT до віртуальної машини, значною мірою покладалися на ІТ-можливості системного інтегратора. Незважаючи на надання підручника, розгортання виявилося складним, оскільки він вирішив не дотримуватися його, оскільки наполягав на тому, що ми помилялися. У результаті ми взяли справу в свої руки, навчилися програмувати ПЛК і самостійно змінили код.
Примітка: системний інтегратор, який ми обрали, був не маленьким, налічував кілька сотень співробітників, але мав лише одного «ІТ експерта». Коли ми надали функціональний підручник, цей експерт зациклювався на розділі свого посібника з програмування PLC щодо Azure IoT Hub. Це було спричинено тим, що наш брокер MQTT Mosquitto працював на віртуальній машині Azure, і “експерт” не розумів різниці (обидві URL-адреси закінчувалися на “azure.com”, тому має бути однаково). Замість використання наміченого методу підключення з сертифікатами, він продовжував запитувати SAS-токен і наполягав, що наш підручник був неправильним.
Це рішення, навіть якщо зрештою розгортання було успішним, очевидно, не відповідало нашим вимогам, оскільки воно все ще залежало від зовнішніх можливостей і знань, а також, очевидно, надто складного налаштування для фактичного використання. Додатково до високої вартості початкового дизайну (близько 12 тис. на пристрій!) було неможливо покладатися на зовнішніх системних інтеграторів, що спонукало нас створити вдосконалену версію.
Спираючись на наш досвід попереднього розгортання, ми самостійно розробили другу версію FactoryCube, уникаючи покладення на системних інтеграторів. В основі цієї версії був промисловий Raspberry Pi (RevolutionPI), який значно знизив витрати. Система також включала блок живлення, маршрутизатор і мережевий комутатор для підключення.

рис.5. Наша друга версія Factory Cube
Raspberry Pi запускав локальний Docker Compose, Node-RED і кілька інших інструментів для вилучення даних. Дані знову були направлені до тієї ж віртуальної машини Azure для подальшої обробки, цього разу вже з Pi за допомогою MQTT. У цій ітерації ми вибрали датчики ifm, підключені до шлюзів IO-Link, які передають дані датчиків через Ethernet безпосередньо на FactoryCube. Щоб знайти IO-Links у мережі та отримати доступ до даних, ми розробили спеціальний інструмент під назвою SensorConnect, який використовується й сьогодні.

рис.6. Модернізований світловий бар’єр від ifm, розміщений на металургійному заводі на верстаті плазмового різання
Датчики та IO-Link виявилися високонадійними, стійкими та простими в установці на місці, що зробило систему більш гнучкою. Ми не пошкодували про своє рішення використовувати апаратне забезпечення ifm і продовжуємо його використовувати. У цій версії ми поступово перенесли більше логіки та обробки на периферійний пристрій і відійшли від цілком хмарного підходу. Цей перехід був досягнутий завдяки використанню Node-RED, інструменту, який хвалили інженери OT, але часто критикували розробники. Для нас це являє собою оптимальний баланс між зручністю використання для OT та автоматизацією, стабільністю та масштабованістю.
Для нас хороші альтернативи до Node-RED є: HighByte, Crosser і benthos. Щоб дізнатися більше про Node-RED, подивіться нашу статтю Node-RED у промисловому Інтернеті речей: зростаючий стандарт
Підводний камінь 6: неправильне використання збірки Docker-Compose та логіки програми Python
Під час розгортання нових проектів ми зіткнулися з труднощами під час створення всіх необхідних контейнерів Docker на пристроях Edge і підтримки узгоджених версій програмного забезпечення на них. Ми підключили SSH до пристроїв, розгорнули логіку програми на Python і запустили docker-compose build.
Коли ми протягом тривалого часу налаштовували численні периферійні пристрої, виникали невідповідності версій програмного забезпечення, оскільки під час розгортання випускалися оновлення. Наприклад, у проекті модернізації двох заводів, оснащених новими датчиками та приблизно 30 периферійними пристроями, ми мали кілька тижнів між встановленнями на кожному заводі. Нові випуски програмного забезпечення за цей час призвели до того, що деякі пристрої працювали безперебійно тоді як інші зіткнулися з проблемами під час роботи необхідних служб.
Щоб вирішити цю проблему, ми запровадили контейнерний реєстр Docker і використали закріплені версії програмного забезпечення, ефективно усуваючи помилки, пов’язані з помилками чи несумісністю. Ми максимально перенесли логіку програми з Python (програмування) на Node-RED (конфігурація).
Крім того, ми вирішили перейти з Raspberry Pi на IPC як нову платформу для третьої версії FactoryCube. Ця зміна забезпечила нам збільшення обчислювальної потужності на периферійних пристроях і архітектуру x86 для покращеної сумісності.
 рис.7. Зображення OnLogic K300
рис.7. Зображення OnLogic K300
Підводний камінь 4 (2/2): виклики з підходом, орієнтованим на хмару
Повнохмарний підхід створив проблеми для певних випадків використання та навіть зробив деякі сценарії нездійсненними. Покладання виключно на хмарну обробку даних призвело до неузгодженості розрахунків через повну залежність від стабільного підключення до Інтернету. Нестабільність мережі може спричинити дрейфи між даними, доступними на Edge та доступними в хмарі. В одному випадку ми відобразили стан машини на індикаторі поруч із виробничою лінією. Дані датчиків надсилалися з периферійного пристрою в хмару для обробки, яка визначала, працює машина чи ні, перш ніж відправляти інформацію назад до світлового індикатору. Коли інтернет-з’єднання було нестабільним, індикатор не працював, незважаючи на його близькість до периферійного пристрою, що значно погіршувало сприйняття клієнтами нашого рішення.
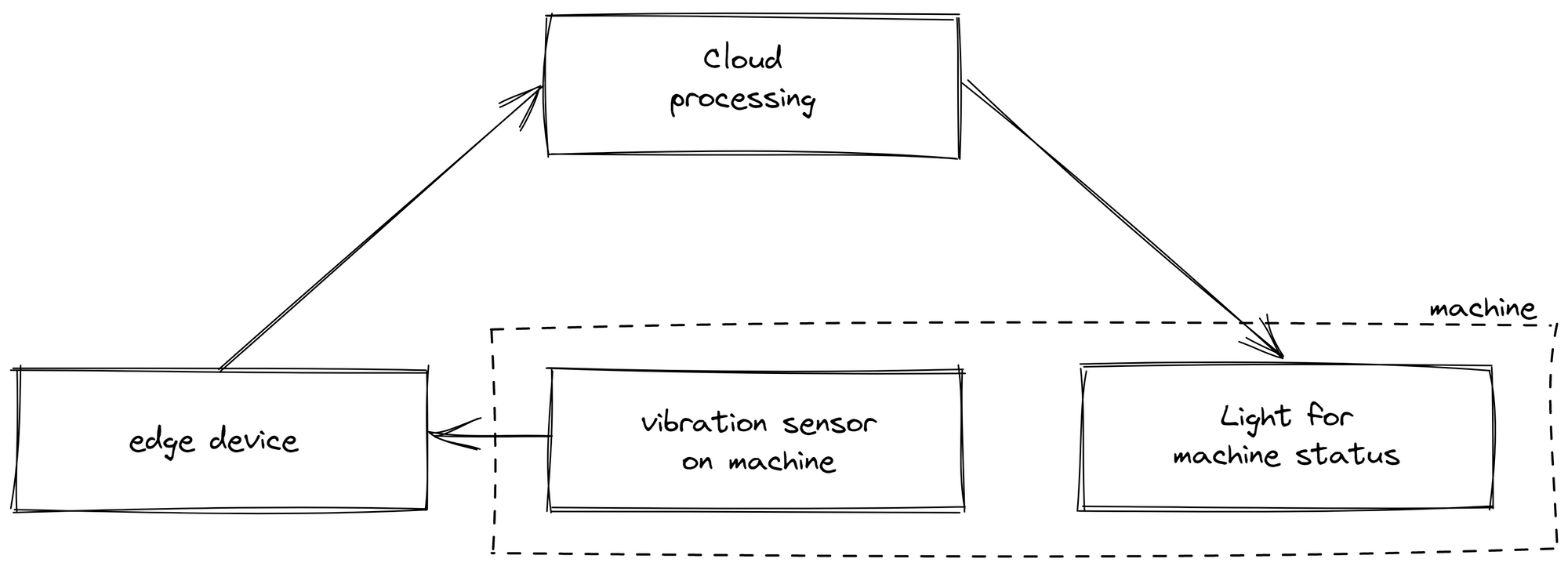
рис.8. Структура стану машини, обробленої хмарою
Крім того, цей підхід не тільки обмежив логіку на Edge, але й ускладнив контекстуалізацію даних. Оскільки в хмару надсилалися лише необроблені дані, згодом вони потребували інтерпретації. Це виявилося неефективним, оскільки розгортання та аналіз даних виконувалися різними особами в різних місцях. Наприклад, стан машини визначався датчиком вібрації з різними станами, що відповідають різним рівням вібрації. Людина, яка створює логіку в хмарі, може не обов’язково знати, які дані вібрації вказують на певний статус.
Після цього досвіду ми вирішили відійти від хмарного підходу для підключення та обробки даних. Ми вирішили запровадити центральний брокер повідомлень (варіант 3 у примітці знизу, див. також зображення нижче), в противагу зв’язку через базу даних (варіант 1) або керування потоком даних через виклики сервісу(варіант 2). На нашу думку, обидві альтернативи мають значні недоліки, такі як неможливість виконувати обробку потоку в реальному часі - при варіанті з базою даних, або призвести до утворення спагетті-діаграм - заплутаних та складних структур зв’язків між компонентами системи, що ускладнює їхнє адміністрування та розуміння - у випадку використання сервісв. Посередник повідомлень, хоч і представляє центральний компонент, спрощує інтеграцію нових служб або машин, оскільки їм потрібно підключитися лише до однієї частини програмного забезпечення та не покладатися на інші з’єднання, як у традиційних структурах.
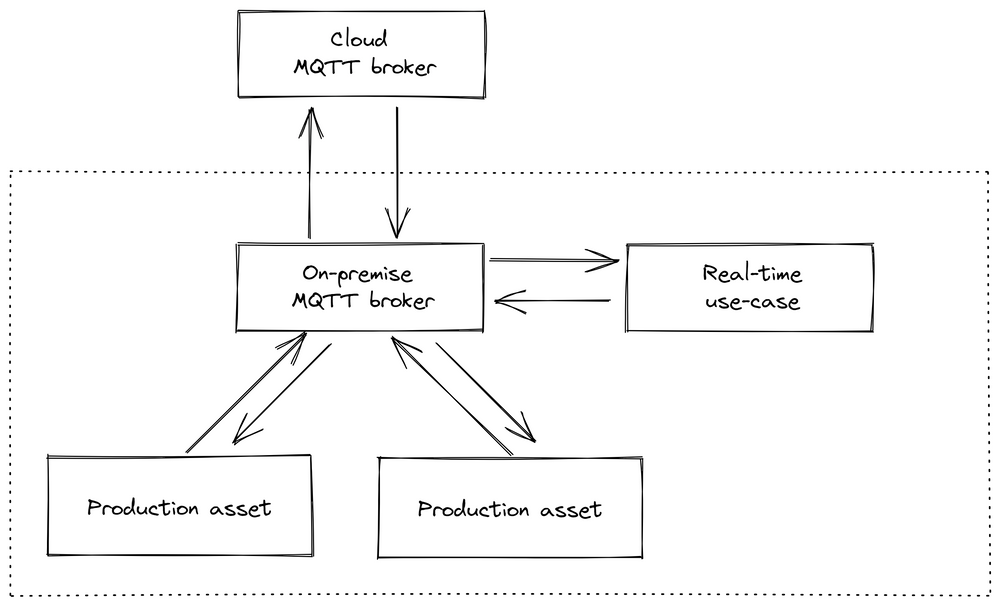 рис.9. Інфраструктура, орієнтована на завод
рис.9. Інфраструктура, орієнтована на завод
Додаткова примітка. У книзі Мартіна Клеппманна «Проектування програм із інтенсивним використанням даних» визначено чотири потенційні будівельні блоки для програм із інтенсивним використанням даних:
- Довгострокові бази даних для зберігання даних
- Короткочасні кеші для прискорення довгих операцій
- Блоки потокової обробки для безперервної обробки та обміну даними
- Блоки пакетної обробки для періодичної обробки пакетів даних
Щоб поєднати ці будівельні блоки, існує три загальні архітектурні підходи:
Варіант 1: Потік даних через бази даних (наприклад, Historian): обробка потоку в реальному часі неможлива. Варіант 2: Потік даних через виклики сервіси: може спричинити спагетті-діаграми, якщо їх масштабувати та не задокументувати належним чином. Варіант 3. Потік даних через асинхронну передачу повідомлень (наприклад, Apache Kafka, HiveMQ або RabbitMQ): представляє брокер повідомлень, який іноді називають «Pub/Sub» або «Unified Namespace»
У виробничих застосуваннях, які часто працюють протягом 10-20 років, здатність легко додавати або видаляти компоненти має вирішальне значення. Ця гнучкість запобігає спагетті-діаграмам і дозволяє обробляти дані в реальному часі, що робить використання брокера повідомлень або «уніфікованого простору імен» часто найкращим вибором. Однак це компроміс між ремонтопридатністю (простотою) і еволюційністю. Додавання нового компонента до загального стеку збільшує ймовірність відмови, але забезпечує гнучкість обміну окремими будівельними блоками.
Додаткову інформацію про архітектуру, який брокер MQTT вибрати, можна знайти в нашій статті Порівняння брокерів MQTT .
Ми вибрали MQTT як нашого першого брокера через його простоту та здатність обробляти мільйони пристроїв, і ми впровадили керовану подіями архітектуру з одним брокером на фабрику. Цей підхід зменшив нашу залежність від підключень до Інтернету, покращив прозорість даних і полегшив інтеграцію нових варіантів використання, таких як обробка даних на рівні Edge. Різні заводи можна було з’єднати через додатковий хмарний брокер MQTT, який керував потоком даних між заводами.
Ця структура перемістила більше логіки та обробки даних на пристрій Edge і зробила перехід від Raspberry Pi необхідним, оскільки була потрібна більша обчислювальна потужність на рівні Edge.
2020-2021: виклики розгортання та надійності
У 2020 і 2021 роках ми зазнали значних змін, що призвело до створення United Manufacturing Hub у тому вигляді, в якому він є сьогодні за своєю архітектурою.
Підводний камінь 7: Обмеження Docker Compose
У міру розвитку нашої архітектури та появи нових проектів ми дедалі частіше стикалися з проблемами Docker Compose. Хоча це дозволяло нам керувати нашими мікросервісами, це вимагало значного ручного втручання, що ускладнювало ефективне масштабування наших операцій.
Наприклад, припустімо, що вам потрібно керувати 20-30 периферійними пристроями для модернізації, кожен з яких потребує підключення, бази даних і можливостей візуалізації. Кожен пристрій має використовуватися протягом трьох місяців для кожного клієнта з індивідуальними налаштуваннями для вимірювання OEE, а потім повертатися до нас. Після повернення кожен пристрій потрібно було повернути до стандартних налаштувань. Під час використання Docker Compose для кожного з цих периферійних пристроїв необхідно виконати наступні кроки:
- Повторно/інсталювати операційну систему.
- Клонувати репозиторій за допомогою файлу Docker Compose.
- Внести незначні коригування та виконати компонування докерів (уникаючи збірки компонування докерів, як згадувалося в Pitfall 6).
- Увійти у InfluxDB, отримати згенерований секрет, перейти до Grafana та додати його як джерело даних.
- Виконати інші «менші налаштування», такі як імпортування шаблонів, зміна конфігурацій за замовчуванням тощо.
Ці, здавалося б, незначні завдання разом зайняли значний час і зусилля. Більше того, навчання персоналу налаштуванню цих пристроїв призвело до неминучої появи помилок, чи то через неправильний вибір майстра налаштування, чи через друкарські помилки. Як наслідок, пристрої часто доводилося налаштовувати заново, що ще більше витрачало ресурси.
Щоб вирішити ці проблеми, ми перейшли до більш надійного рішення: Kubernetes у формі k3s у поєднанні з Helm і k3os як операційною системою. Ця зміна дозволила нам повністю автоматизувати кроки з 1 по 5. Нам просто потрібно було ввести всі вимоги в один файл і натиснути «provision». Це значно зменшило ймовірність помилок і підвищило надійність системи. Це також покращило відтворюваність - у разі збою апаратного забезпечення або помилки користувача ідеальне налаштування можна було відновити лише за 20 хвилин.
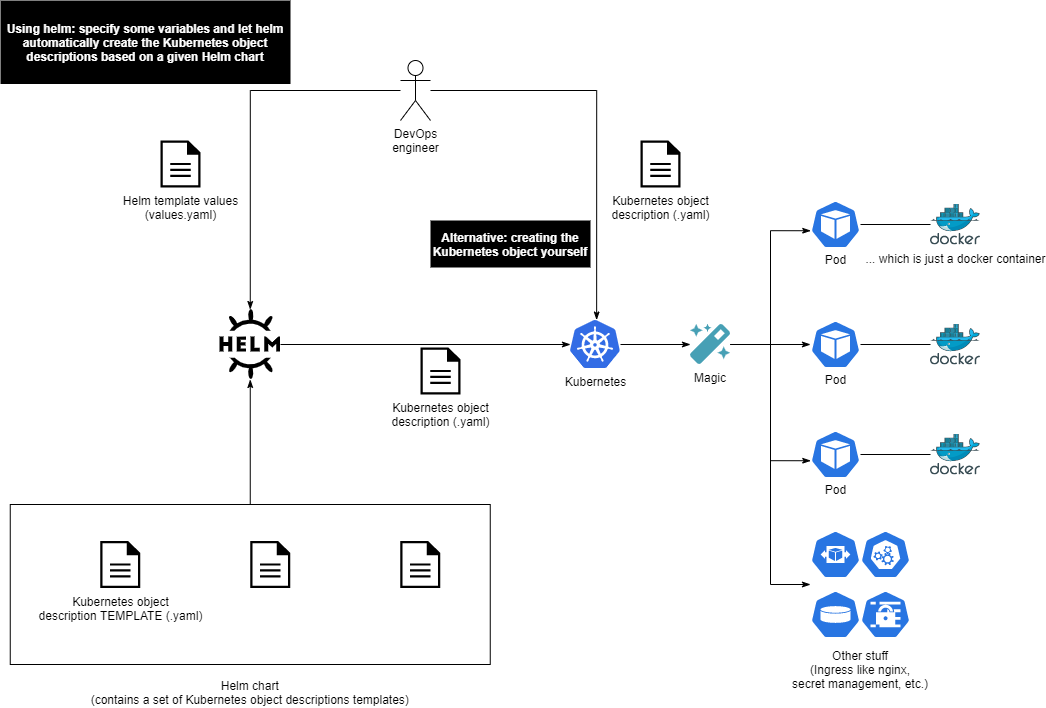 рис.10. Як Kubernetes, Helm та Docker працюють сумісно
рис.10. Як Kubernetes, Helm та Docker працюють сумісно
Додаткова примітка. Kubernetes — це платформа оркестровки контейнерів, яка спрощує розгортання, масштабування та керування контейнерними програмами. У нашій архітектурі ми використовуємо Kubernetes у поєднанні з Helm. Helm charts забезпечує зручний спосіб упаковки та розповсюдження застосунків Kubernetes, дозволяючи нам визначати бажаний стан наших програм і ефективно керувати їх розгортанням. Він дозволяє користувачам визначати бажаний стан (наприклад, «Я хочу мати одну програму на основі цього образу Docker із цими змінними середовища…») і автоматично створює відповідні описи об’єктів Kubernetes для досягнення цього стану. Це можна вважати подібним до файл docker-compose.yaml.
Додаткову інформацію про Docker, Kubernetes і Helm можна знайти у нашому навчальному центрі
Підводний камінь 8: нестабільність InfluxDB і реляційних даних
 рис.11. TimescaleDB vs InfluxDB
рис.11. TimescaleDB vs InfluxDB
Наші пошуки оптимальної бази даних привели нас до переходу від InfluxDB до TimescaleDB. Наші проекти вимагали обробки як часових рядів, так і реляційних даних, що часто створює труднощі. Спочатку ми вибрали InfluxDB через його переконливий маркетинг і наше знайомство з ним за проектами домашньої автоматизації. Він пропонує зручний інтерфейс і безперервні запити для обробки даних, що робить його ідеальним для наших потреб. Однак незабаром ми виявили, що це було помилкове рішення.
В одному проекті нам довелося обробляти необроблені машинні дані, наприклад перетворювати дані світлового бар’єру в стан машини. Одночасно нам потрібно було зберігати інформацію про зміни, замовлення та продукти за допомогою InfluxDB.
М’яко кажучи, InfluxDB не підходив для такого сценарію використання: безперервні запити часто не виконувалися, часто без жодного повідомлення про помилку. Flux, мова запитів InfluxDB, була відносно новою та більш складною для обробки порівняно з SQL. Нам довелося писати сценарії Python для обробки даних через обмеження Flux – завдання, які були б простими в SQL. Цей досвід підкреслив необхідність змін.
**Примітка: ** InfluxDB, молодий стартап, залучив значне фінансування. Проте за останні п’ять років його двічі повністю переписували.
Хоча переписування програмного забезпечення може вирішити фундаментальні проблеми та запровадити нові функції, вони часто призводять до несправних змін API та непередбачених помилок. Це призводить до додаткових проектів міграції, що забирає дорогоцінний час і створює ризики, такі як простой системи або втрата даних. Ми помітили тенденцію InfluxDB віддавати пріоритет розробці нових функцій над стабільністю продукту, щоб виправдати своє значне фінансування. Наприклад, запровадження власного інструменту візуалізації, здавалося, поставило під загрозу стабільність, і адаптація до зміни API виявилася вимогливою.
Крім того, InfluxDB пропонує горизонтальну масштабованість лише у своїй платній версії, що потенційно перешкоджає масштабному розгортанню через ризик блокування постачальника.
Зрештою ми обрали TimescaleDB як нашу нову базу даних, яка побудована на PostgreSQL. PostgreSQL вже використовувався та розвивався протягом понад 25 років і довів свою надійність і робастність. Частково це можна пояснити його здатністю продовжувати працювати навіть у разі збою. Ще однією важливою перевагою є легкість, з якою його можна горизонтально масштабувати на кількох серверах. Ця зміна забезпечила велике полегшення, дозволивши нам зосередитися на нашому продукті без постійного виправлення несправних змін API. Для отримання додаткової інформації та детального порівняння перегляньте статтю нашого блогу.
Підводний камінь 9: покладатися виключно на MQTT або Kafka, замість використання обох
У міру розвитку нашої розробки ми виявили важливий перехід від використання MQTT як нашого єдиного брокера повідомлень до поєднання MQTT і Kafka. Ми зробили цей перехід, тому що MQTT, хоч і надійний для підтримки з’єднань із великою кількістю пристроїв, не був розроблений з урахуванням відмовостійких і масштабованих застосунків обробки потоків. Крім того, ми зіткнулися з проблемами з мостами MQTT. Однак повна заміна MQTT на Kafka також не була б ідеальною, оскільки Kafka не особливо підходить для вирішення ситуацій, коли підписники або видавці часто виходять з мережі, а потім повертаються в Інтернет.
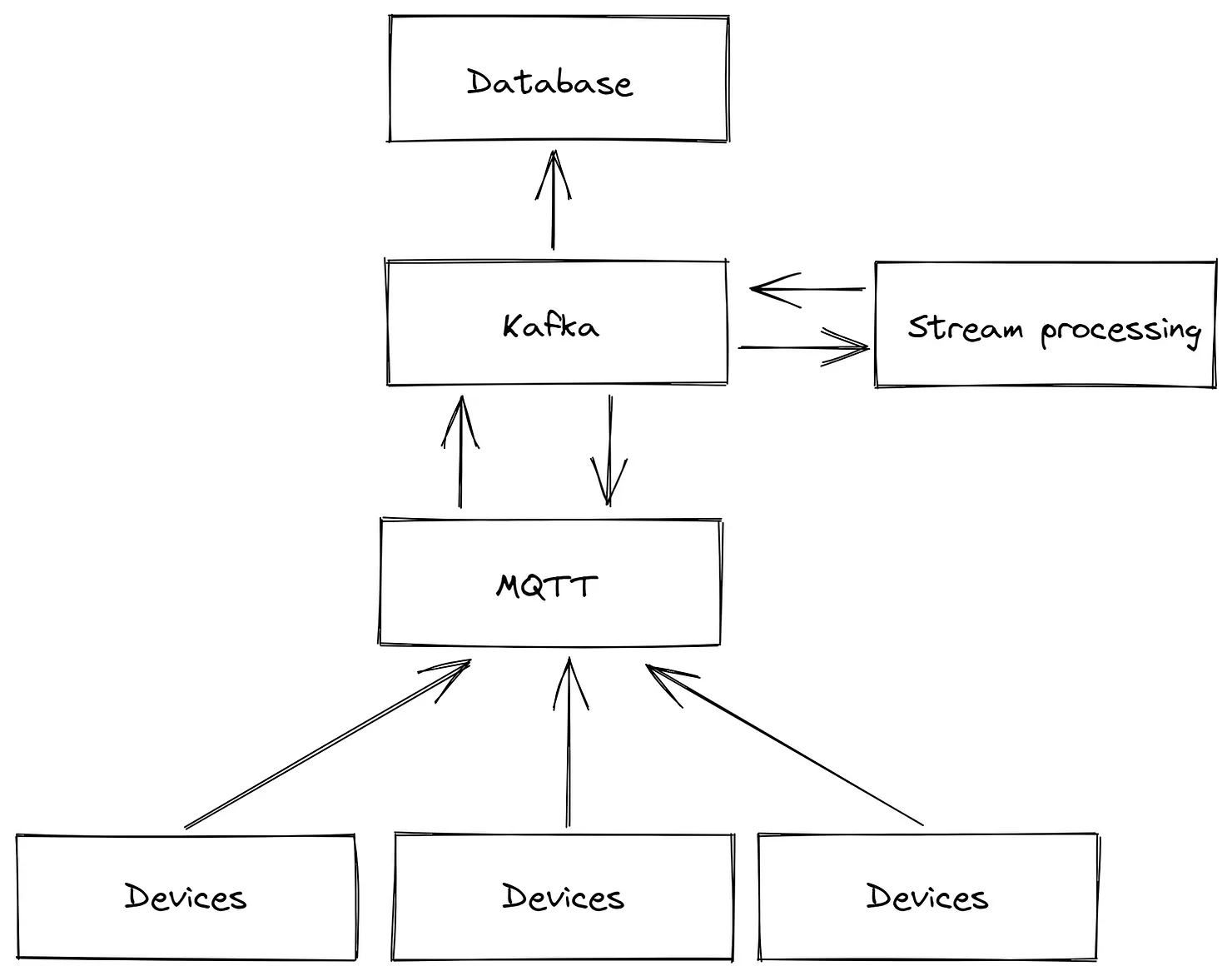 рис.12. MQTT –> Kafka дозволяє підключати мільйони пристроїв, водночас надійно обробляючи вхідні дані
рис.12. MQTT –> Kafka дозволяє підключати мільйони пристроїв, водночас надійно обробляючи вхідні дані
Додаткова примітка: обробка потоку передбачає отримання даних від брокера, їх обробку та надсилання назад. У рідкісних випадках на Edge можуть виникати проблеми, наприклад перезавантаження пристрою, проблеми з мережею або перевантаження мікросервісу. Ці сценарії можуть призвести до пошкодження черги, дублювання, втрати чи необроблених повідомлень або комбінації кількох помилок. Стандартні інструменти Apache, такі як Kafka, Flink і Spark, створені для ефективної обробки цих помилок.
Ось практичний приклад, який ілюструє обмеження MQTT: розглянемо просту установку, що включає світловий бар’єр і два мікросервіси. Мікросервіс A надсилає повідомлення підрахунку щоразу, коли продукт перетинає світловий бар’єр. З іншого боку, мікросервіс B збільшує кількість оброблених продуктів кожного разу, коли отримує таке повідомлення. Якщо Microservice B отримує занадто багато повідомлень одночасно, він може аварійно завершити роботу та перезапуститися, що призведе до втрати повідомлень. Імовірність зіткнутися з такими граничними корпусами зростає з кожним додатковим пристроєм, що робить цю проблему дедалі більшою.
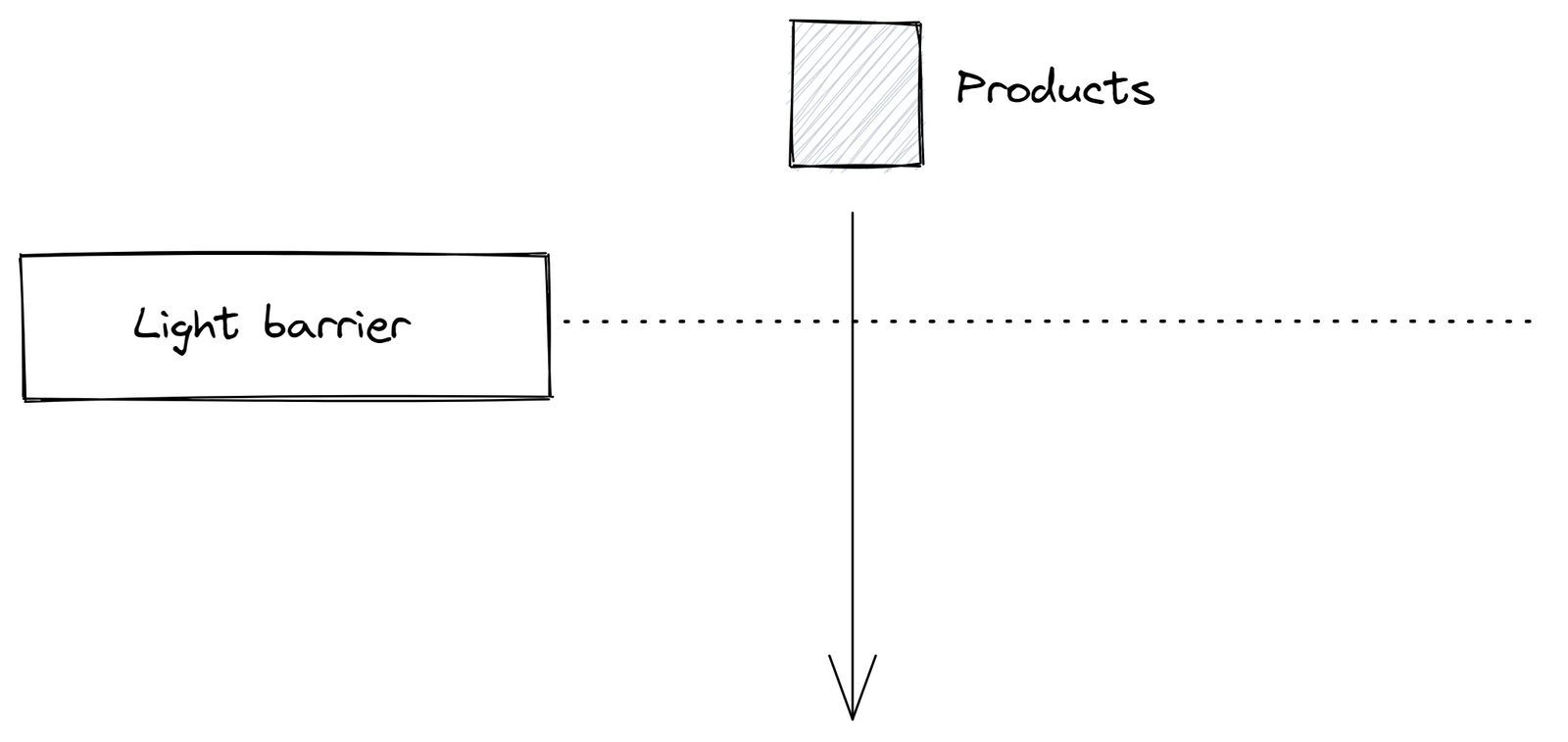
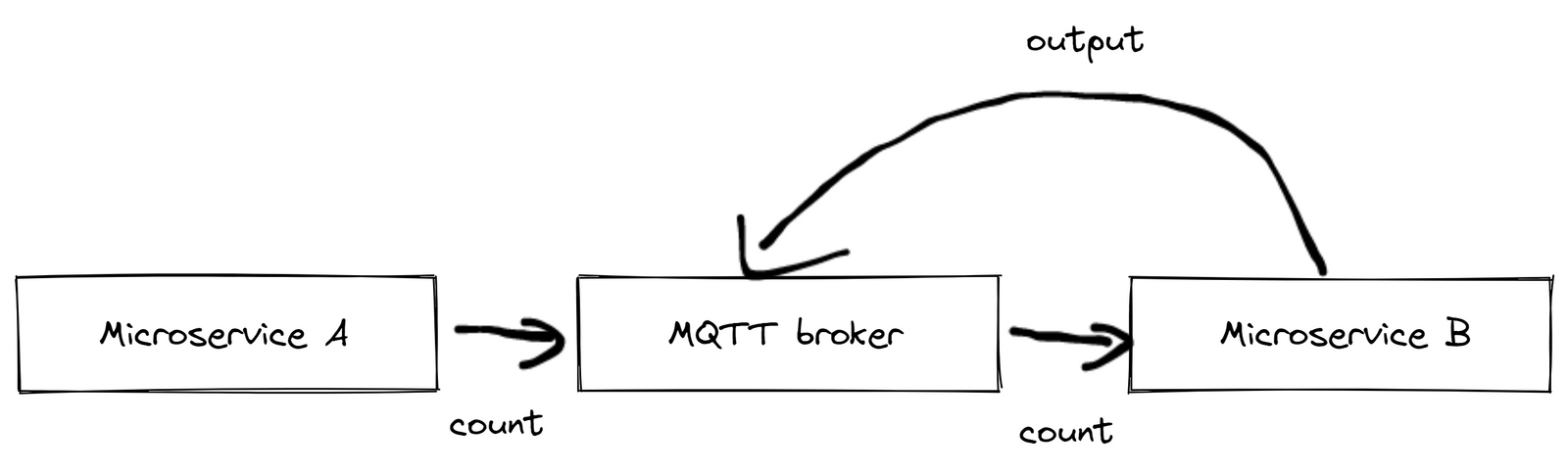 рис.13. Структура мікросервісів A і B і світловий бар’єр
рис.13. Структура мікросервісів A і B і світловий бар’єр
Kafka пропонує рішення, записуючи події у файл журналу, забезпечуючи гарантоване впорядкування повідомлень, нульову втрату повідомлень і високоефективну одноразову обробку навіть за складних обставин.
Ми зупинилися на суміші Kafka та MQTT, де повідомлення спочатку передаються через MQTT, а потім обробляються через Kafka для потокової обробки. Цю архітектуру визнано найкращою галузевою практикою для керування та обробки великомасштабних даних. Це захищає від перевантажень мікросервісів, оскільки кожен споживач обробляє дані у власному темпі. У разі збою перезапущена служба може просто продовжити роботу з того місця, де вона зупинилася, підвищуючи надійність системи.
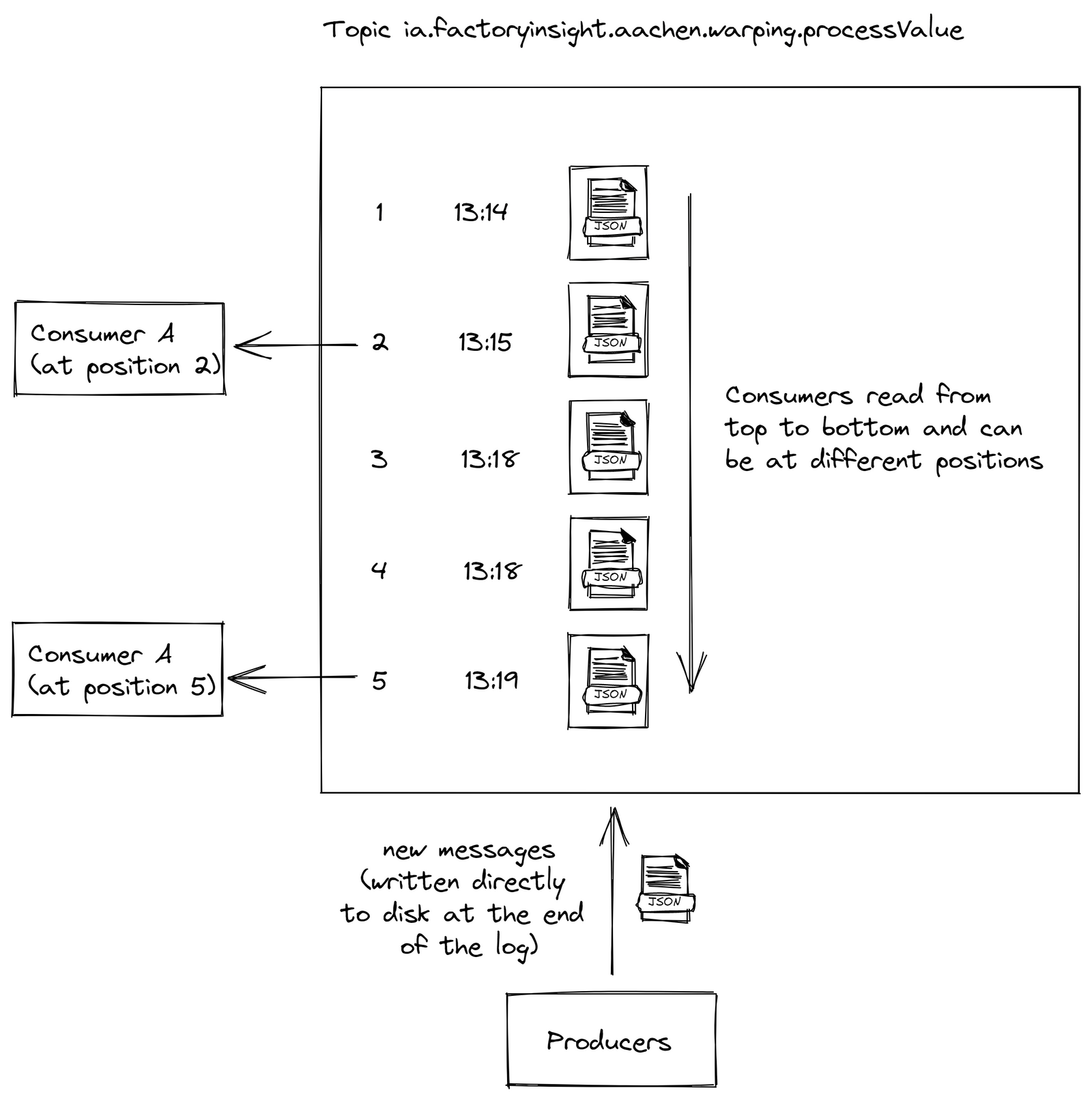 рис.14. Структура підходу Кафки з лог-файлом
рис.14. Структура підходу Кафки з лог-файлом
Більше інформації про MQTT і Kafka? Ознайомтеся зі статтею нашого блогу Інструменти та методи для масштабованої обробки даних у промисловому Інтернеті речей
Підводний камінь 10: Спроба побудувати власний VPN за допомогою OpenVPN або подібних інструментів

рис.15. Tailscale доступний як пропозиція з відкритим вихідним кодом або як розміщена пропозиція SaaS
Одне менш масштабне, але критичне оновлення, яке ми внесли, стосувалося заміни OpenVPN на Tailscale для наших потреб VPN. Встановлення VPN для доступу до віддаленого пристрою може стати досить складним за допомогою OpenVPN, особливо коли потрібні вихідні з’єднання. Ми використали Docker-Compose для OpenVPN, який створив унікальний сервер OpenVPN для кожного пристрою, забезпечуючи повну ізоляцію між пристроями (оскільки вони були розташовані на різних майданчиках клієнтів). Це налаштування вимагало ретельної конфігурації OpenVPN, трудомісткого процесу, який зрештою був непотрібним для наших потреб. Ми зосереджувалися не на високошвидкісному з’єднанні, а на надійному з’єднанні для екстрених ситуацій.
Додаткова примітка: Віртуальна приватна мережа (VPN) забезпечує безпечне з’єднання між пристроями через Інтернет, дозволяючи безпечно передавати дані. Це особливо важливо для підприємств з віддаленими операціями, яким потрібне безпечне та стабільне з’єднання. Традиційні рішення VPN, такі як OpenVPN, можуть бути досить складними для налаштування та керування, особливо для вихідних з’єднань, що може призвести до потенційних ризиків для безпеки, якщо їх не впровадити належним чином.
З нашого досвіду Tailscale виявився більш ефективним вибором для наших вимог. Він стабільно добре працює, навіть через корпоративні брандмауери, якими зазвичай важко орієнтуватися.
2022 - зараз: поточний стан і майбутнє United Manufacturing Hub
За останні кілька років наша фундаментальна архітектура з відкритим вихідним кодом продемонструвала високі показники стабільності та надійності, вимагаючи лише незначних коригувань. Ключові зміни включають заміну VerneMQ на HiveMQ для підвищення прийнятності на великих підприємствах. Ми також перейшли з k3os на Flatcar після несподіваного припинення підтримки k3os. Ще однією помітною зміною став перехід від Kafka до RedPanda, спрямований на покращення зручності обслуговування на периферійних пристроях.
Більше інформації про Flatcar? Перегляньте статтю нашого блогу Flatcar як операційна система промислового IoT
На даний момент ми працюємо над трьома темами:
- Розробка узгодженої моделі даних, сумісної з ISA95. Наша існуюча модель даних, незважаючи на те, що вона є недосконалою, виявилася ефективною в різних галузях, насамперед завдяки своїй простоті для інтеграції в цех. Наприклад, вона ніколи не вимагає даних, які зазвичай недоступні на рівні ПЛК, таких як OEE або детальна історія замовлень. Натомість вона використовує встановлені стандарти, такі як Weihenstephaner або PackML, тісно узгоджені з доступними даними ПЛК. Наразі ми узгоджуємо цю модель зі стандартами ISA95, одночасно стандартизуючи правила іменування в MQTT, базі даних і API. Ви можете знайти попередній перегляд цієї моделі тут. Ми також уважно стежимо за розробкою Sparkplug B, зокрема за її потенціалом для корисних навантажень JSON і гнучких структур тем.
- Потокова обробка та контекстуалізація даних доступна для інженерів OT. Хоча ІТ-орієнтовані інструменти, такі як Spark і Flink, пропонують масштабованість, вони не дуже зручні для персоналу OT, який зазвичай відповідає за введення логіки обчислень і виконання контекстуалізації. З іншого боку, багато орієнтованих на OT інструментів, які ми оцінювали, не вміють застосовувати найкращі ІТ-практики, тому їх важко масштабувати та керувати. Ця проблема спонукала нас до розробки власного сервісу підключення OPC-UA, про який ви можете дізнатися тут. Зараз ми вивчаємо різні можливості в цій сфері.
- Створення комплексної консолі керування. Ми визначили загальну проблему для виробничих компаній: невизначеність щодо розподілу відповідальності за окремі будівельні блоки – від периферійних пристроїв до віртуальних машин і до програм. Це домен OT, технічного обслуговування, IT чи хмарного відділу? Ця неоднозначність часто призводить до непотрібних витрат або повного уникнення такої архітектури. Нашим рішенням є розробка консолі керування, уніфікованої платформи, яка контролює всі компоненти стеку. Від надання нових пристроїв і моніторингу працездатності апаратного забезпечення, мікросервісів, потоків даних і додатків до налаштування версії й журналів аудиту — усе з одного місця. Якщо вам цікаво дізнатися більше, не соромтеся звертатися до нас!
Резюме
Розробка та впровадження стійкої ІТ/ОТ інфраструктури є багатогранним завданням, яке вимагає тонкого розуміння як ІТ, так і ОТ доменів, розумного балансу вартості та якості та здатності передбачати потенційні виклики. Розробляючи United Manufacturing Hub, ми подолали лабіринт перешкод і адаптацій, засвоївши на цьому шляху безцінні уроки. Ось десять важливих пасток, з якими ми зіткнулися та впоралися:
- Гармонізація ІТ-рішень і ОТ-рішень: чіткі відмінності між ІТ-і ОТ-доменами створюють проблеми в інтеграції та масштабуванні різних рішень, що потребує точного розуміння обох.
- Неправильне уявлення про низький код: рішення з низьким кодом вимагали значного кодування для складних індивідуальних налаштувань, що кидало виклик початковому сприйняттю цих інструментів як прості в інтеграції та зручні для користувача.
- Недооцінка важливості сертифікації OT: спроба рентабельних рішень із використанням несертифікованого обладнання OT призвела до збоїв і труднощів під час усунення несправностей, зводячи нанівець початкову економічну вигоду.
- Проблеми з підходом, орієнтованим на хмару: спроба модернізувати підхід, який використовує перш за все хмару, наштовхнулася на такі проблеми, як нестабільність мережі, проблеми з доступом і обмеження налаштування. Повністю хмарний підхід призвів до неузгодженості розрахунків і повної залежності від стабільного підключення до Інтернету.
- Переоцінка ІТ-компетентності системних інтеграторів OT: незважаючи на простоту нашого рішення, його розгортання часто вимагало серйозних ІТ-знань, що підкреслює важливість не переоцінювати ІТ-компетентність системних інтеграторів OT.
- Неправильне використання збірки Docker-Compose та логіки додатків Python: розгортання нових проектів і підтримка узгодженості версій програмного забезпечення на периферійних пристроях виявилося складним при використанні логіки додатків Docker Compose та Python.
- Обмеження Docker Compose: Docker Compose виявився неефективним для керування мікросервісами, особливо під час масштабування операцій.
- Перехід від InfluxDB до TimescaleDB: нездатність InfluxDB ефективно обробляти як часові ряди, так і реляційні дані, у поєднанні з частими збоями, вимагали переходу до TimescaleDB.
- Виключно покладаючись на MQTT або Kafka, замість того, щоб використовувати обидва: використання лише MQTT або Kafka не вдалось, коли справа дійшла до масштабованих додатків обробки потоку, що вимагало поєднання обох.
- Спроба побудувати власний VPN за допомогою OpenVPN або подібних інструментів: увімкнувши створення VPN, OpenVPN було складним і складним, особливо для вихідних з’єднань.
Наша подорож через ці підводні камені сформувала United Manufacturing Hub у міцну та надійну платформу, яка дозволяє керувати складнощами проектування IT/OT інфраструктури. Оскільки ми продовжуємо розвиватися та впроваджувати інновації, наш досвід спрямовує нас у нашій місії створити зручну та ефективну інфраструктуру IT/OT.
Хочете бути в курсі подій? Підпишіться на нашу розсилку!
Хочете спробувати United Manufacturing Hub? Перегляньте це!