TI40
Технології індустрії 4.0. Лекції Автор і лектор: Олександр Пупена
| <- до лекцій | на основну сторінку курсу |
|---|---|
8. Хмарні сховища та аналітика
8.1. Сховища в IIoT
У інфраструктурі промислового інтернету речей дані необхідно не тільки обробляти, але і зберігати. Враховуючи що в типову трирівневу структуру IIoT входять різні типи пристроїв та ПЗ, можна виділити кілька місць (сховищ), де дані можна зберігати.
- IoT Device. Нагадаємо, що під IoT Device ми розуміємо будь який пристрій, що надає доступ до даних по цифровому інтерфейсу (ПЛК, ПК, розумні польові пристрої, розумні датчики і т.ін). Дані можуть зберігатися на таких пристроях у вигляді файлів або окремих записів в пам’яті. Наприклад, це може бути файл журналу подій або осцилограми на карті ПЛК. Або в даному контексті це може бути навіть ціла база даних трендів SCADA/HMI. Таким чином ретроспективні дані можна витягувати прямо зі сховища.
-
Edge Gateway. Дані можна також зберігати в Edge Gateway. Це можна робити для можливості буферизації даних перед відправкою в хмару, або для можливості обробки ретроспективних даних безпосередньо за місцем (Edge обрахунки або туманні обчислення), або для виконання функцій доступу до трендів або журналів через веб за місцем.
- Хмарні сховища або виділені сервери в Інтернет. Збереження даних в Інтернеті передбачає можливість їх використання в різноманітних сервісах з доступом 24/7 та збереженням на великі періоди часу.
В такій системі, одні і ті самі дані можуть зберігатися в кількох місцях. Припустимо дані журналів можуть розміщуватися на IoT Device але при цьому їх треба дублювати в сховищі Edge Gateway для буферизації або/та для відображення в локальних засобах WEB-доступу (з мобільних застосунків) і в той же час записувати в хмарні сховища для їх подальшої обробки в аналітичних сервісах. У цьому випадку виникає питання їх синхронізації.
В залежності від представлення даних та їх призначення сховища можуть мати зовсім різний формат. За призначенням можна в тому числі виділити наступні дані (див. DigTwin):
-
квазістатична інформація про актив, такі як опис пристрою, серійний номер, конфігураційні параметри пристрою, тощо; ця інформація змінюється рідко або взагалі не змінюється
-
часово-базисна інформація: записи трендів та журнали; ці дані постійно змінюються і важливо знати що саме змінилося і коли;
-
різноманітні файли: допомоги, графіка, образи завантажень і т.п., які зберігаються і надаються у атомарному вигляді без аналізу змісту
Для різних даних за призначенням можна використовувати зовсім різні формати сховищ. Розглянемо їх нижче.
8.2. Реляційні СКБД (SQL-подібні)
У якості сховищ можуть використовуватися реляційні базах даних, в яких усі дані представлені у вигляді таблиць, які пов’язані відношеннями (рис.10.1). Ці БД та СКБД які їх обслуговують відомі з інших курсів. На сьогоднішній день вони найбільш популярні і можуть використовуватися як на рівні Edge так і на рівні платформи. У якості мови обробки запитів та маніпулювання даних для таких БД використовується мова SQL, тому такі БД та СКБД прийнято називати SQL-подібними БД.

рис.10.1. Представлення даних у реляційних БД.
Реляційні СКБД звісно можна розгортати на віртуальних машинах, але такі СКБД у великій кількості присутні у якості хмарних сервісів. Серед таких сервісів є DB2, який присутній в IBM Cloud. Для хмарних сервісів IBM, DB2 є сховищем даних для різноманітних функцій статистики. Однак варто зауважити, що згідно останніх тенденцій, багато провайдерів переходять на інші типи сховищ для пришвидшення обробки. Розглянемо принципи використання хмарних сервісів SQL сховищ на прикладі DB2.
DB2 можу використовуватися як на Edge рівні так і на Cloud, з можливістю репліації. У DB2 бази даних організовані як Shema (Схема). Для кожної Схеми є окреме вікно конфігурування (рис.10.2)
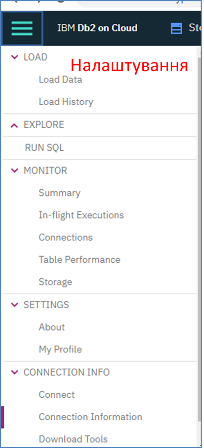
рис.10.2. Вікно конфігурування DB2
Перед використанням DB2 необхідно налаштувати користувача на користування сервісів. Адміністратор за замовченням може створювати бази даних (схеми) але не може маніпулювати ними. Тому спочатку йому необхідно надати дозволи. Для цього на відповідній сторінці Manage -> Access IAM -> Users надається доступ для вибраного користувача (рис.10.3) шляхом визначення прав в Access Polices -> Assign Access.

рис.10.3. Надання доступу користувачу до схеми DB2
Для доступу до схеми необхідно створити сервіс (рис.10.4) та облікові дані для нього (Service Credential рис.10.5)
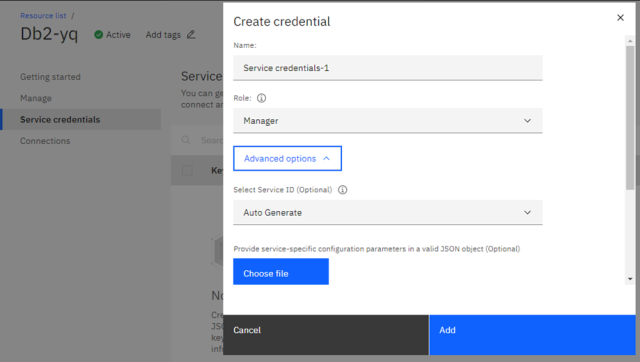
рис.10.4. Створення сервісу для DB2

рис.10.5. Приклад створення облікових даних для доступу до сервісу
Далі безпосередньо у консолі (Manage->Open Console) можна проводити різноманітні маніпуляції з даними, такі як створення інших схем, таблиць, записів та інші маніпуляції в т.ч. через SQL запити.
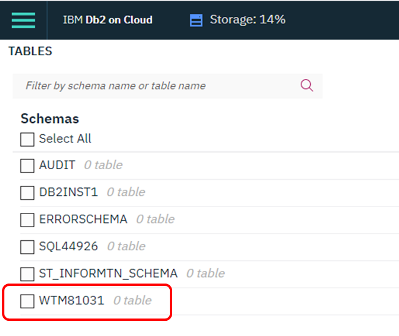
рис.10.6. Робота з консоллю DB2
З рівня Edge до хмарних сервісів DB2 можна доступитися через різноманітні утиліти, які надають можливість у зручному вигляді переглянути та змінити дані без необхідності роботи з часто незручними та повільними ВЕБ-консольними сервісами хмари. Наприклад в утиліту DBeaver для цього достатньо на клієнтську машину завантажити пакет драйверів JDBC (рис.10.7). Після цього в налаштуваннях зв’язку вказується дані, що були задані в облікових даних для доступу до сервісу.
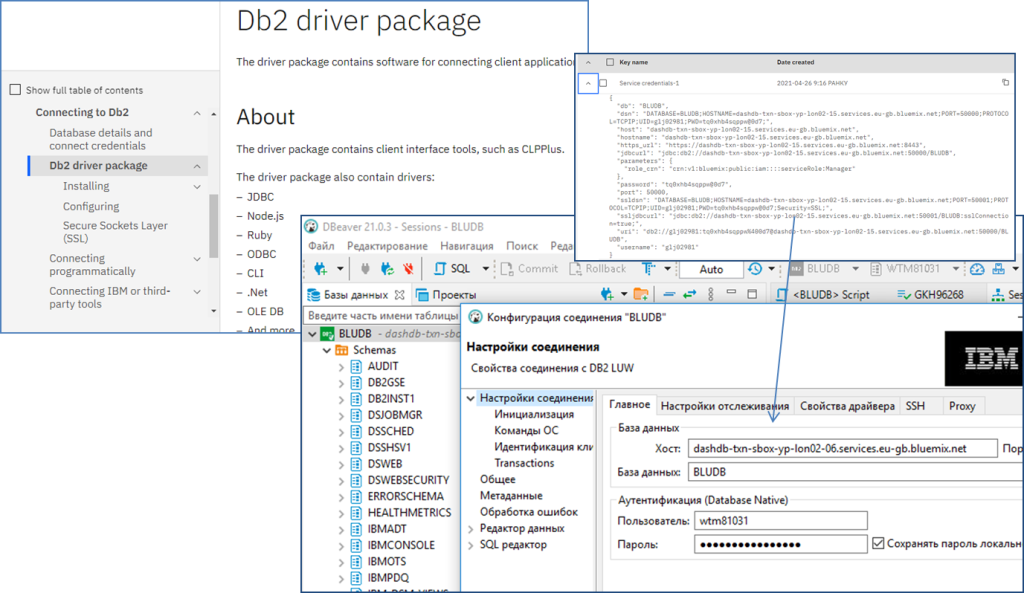
рис.10.7. Приклад налаштування зв’язку з DB2 в DBeaver.
За необхідності підключення інших застосунків можна скористатися драйверами ODBC. Драйвер ставиться з IBM DB2 driver package і доступний в налаштуваннях ODBC (рис.10.8)
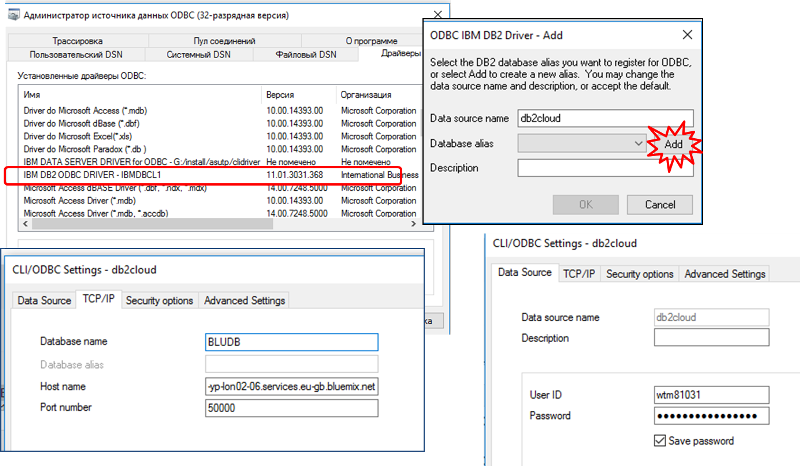
рис.10.8. Налаштування драйверу ODBC для IBM DB2
Далі цей драйвер можна використовувати для різних застосунків, що сумісні з ODBC.
8.3. NoSQL СКБД (document-oriented)
У багатьох випадках для рішень IoT реляційні бази даних в якості сховища не є вдалим варіантом. Причин на це кілька, зокрема:
- таблиці передбачають заздалегідь відому структуру даних, тому якщо дані змінюють свою структуру, вони можуть бути тільки як змінюване поле таблиці, що не зручно при необхідності аналізу зміста поля
- для сховища на базі часу зі збільшенням кількості даних пропорційно збільшується час для пошуку
- реляційні бази даних погано масштабуються вшир, тобто тяжко реалізувати розподілену БД
Тому для різних завдань використовують різні нереляційні сховища, зокрема так звані NoSQL бази даних, Object Storage та Time Series Database. У даній лекції розглядають перші два типи, в наступній лекції - TSDB.
Серед NoSQL БД окремим класом виділяються так звані документо-орієнтовні БД. Основною атомарною одиницею в таких БД є документ. Документ можна порівняти з записом в таблицях реляційної бази даних. Але на відміну від останніх документ може мати довільну структуру. Кожен документ має унікальний в межах БД ідентифікатор - ключ (рис.10.9). У документо-орієнтованих БД зміст документів також аналізується.
Таким чином в таких БД інформація зберігається в напівструктурованому вигляді:
- база даних не потребує попередньо означеної схеми, яка потребується для реляційних БД, оскільки кожен документ створюється за необхідності і може мати довільну структуру
- можна доступитися до частини документу (наприклад за полем)
- з документу можна вилучити інформацію для індексації для пошуку за змістом
-
БД може включати метадокументи для організації індексів, захисту та інших налаштувань
- документи в БД можуть групуватися, будуватися залежності

рис.10.9. Принцип побудови документо-орієнтованої БД
Така організація даних дає певні переваги порівняно з реляційними БД:
-
краща продуктивність для великих об’ємів даних
-
не потребує схеми
-
легше масштабуються, можуть бути децентралізовані
-
можна зберігати неструктуровану інформацію
-
простий інтерфейс
Одним із представників документ-орієнтованої СКБД, яка багато використовується в системах IoT є Couch DB (https://couchdb.apache.org). Це безкоштовне ПЗ, яке ставиться на різні платформи (різні ОС в тому числі на ARM-based), а отже може використовуватися в IoT як на рівні Edge так і на рівні платформи.
Для конфігурування та маніпулювання даними може вкиористовуватися як вбудований ВЕБ-інтерфейс, який називається Fauxton так і REST API. БД будується на базі документів в форматі JSON. Самі СКБД між собою можуть синхронізувати документи у будь-якому напрямку (реплікація master-master) що робить розподілену систему, побудовану на базі неї дуже гнучкою.
Адміністрування Couch DB на Fauxton досить просте (рис.10.10). Для цього необхідно зайти на сторінку адміністрування, наприклад за локальною адресою це буде http://127.0.0.1:5984/_utils/#login. Там можна робити конфігурування, різні операції з БД, документами, індексами, реплікаціями і т.п
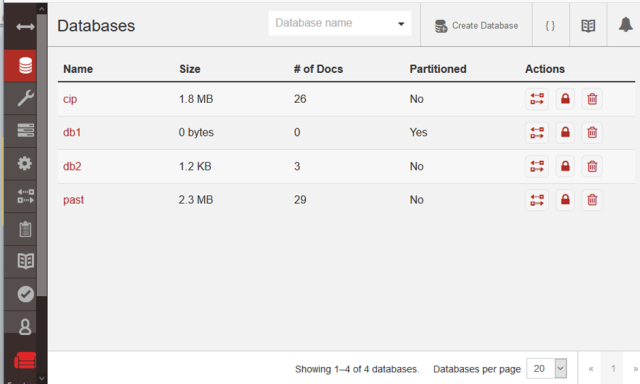
рис.10.10. Зовнішній вигляд консолі CouchDB
Доступні хмарні реалізації CouchDB, зокрема в IBM Cloud він доступний як сервіс IBM Cloudant. Є певні особливості в налаштуваннях та функціонуванні сервісу, але основні принципи залишаються такими ж (рис.10.11)

рис.10.11. Реалізація CouchDB в Clouds - IBM Cloudant
Для маніпуляції та адміністрування REST API надає наступні типи операцій:
-
Server
-
Databases
-
Documents
-
Replication
Так, наприклад, доступ до кореневого документу серверу повертає відповідь в форматі JSON з загальною інформацією про СКБД (рис.10.12).
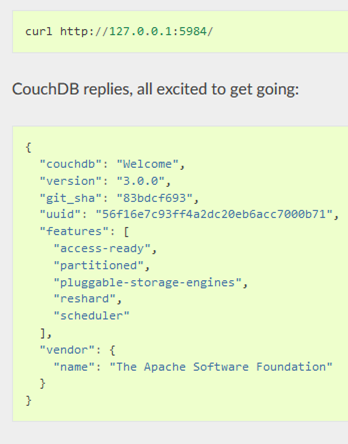
рис.10.12. Відповідь на запит до кореневого документу
Якщо доступ передбачає обмеження то в url задається ім’я користувача та пароль, відповідно до правил базової автентифікації HTTP (рис.10.12). Для створення БД достатньо відправити http запит з методом PUT та іменем створюваної БД (рис.10.12)
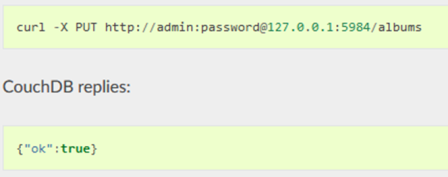
рис.10.13. Запит на створення бази даних
Ось кілька популярних запитів:
GET http://127.0.0.1:5984/_all_dbs- отримати список баз данихPUT http://127.0.0.1:5984/DB_name- створити базу данихGET http://127.0.0.1:5984/DB_name- видалити базу даних
Кожен документ має унікальний в БД текстовий ID, який записується окремим спеціальним полем _id. Це поле створюється при створенні документу і не може змінюватися (рис.10.14) бо це є назвою документу. Її можна задати довільно або отримати унікальний з СКБД унікальний ідентифікатор UUID (GUID). Зміна документа відбувається шляхом його повної заміни. Для того щоб відслідковувати зміни, зокрема з метою реплікації окрім id записується також версія в поле _rev (рис.10.15).

рис.10.14. Перелік документів
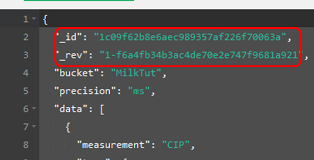
рис.10.15. Обов’язкові поля для документів
Для створення документу використовується запит PUT http://127.0.0.1:5984/dbname/docname 'documentcontent' . Для отримання UUID GET http://127.0.0.1:5984/_uuids. Для отримання документу GET http://127.0.0.1:5984/dbname/docname.
У розподілених системах (рис.10.16) БД обмінюються документами для їх синхронізації. Механізм синхронізації баз даних на одному або різних ПК називається реплікацією. Для налаштування реплікації вказується source (звідки) і target (куди). Якщо в target старіша або відсутня версія ніж в source, буде документ буде замінений.

рис.10.16. Розподілена архітектура
За допомогою реплікації в системах IIoT можна синхронізувати локальні документи в IoT Gateway з відповідними документами на хмарі.
Є можливість зробити реплікацію на постійній основі або за запитому, наприклад відправивши відповідний запит (рис.10.17).

рис.10.17. Запит на реплікацію документу
Для доступу до документу вказується його індекс. Для пошуку документів є спеціальний ресурс REST API find, який забезпечує пошук необхідних документів за вказаними параметрами:
POST /{db}/_find
Пошук може відбуватися за критеріями подібно як це робиться в SQL (рис.10.18):
selector(json)– який забезпечує пошук документу за обєктом JSON в якому вказуються критерії пошуку-
limit (number()– максимальна кількість повернених документів -
skip (number)– відміна перших ‘n’ результатів -
sort (json)– масив JSON з вказівкою сортування fields (array)– масив JSON з полями результату
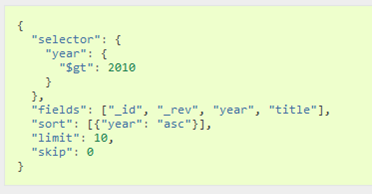
рис.10.18. Доступ до даних за індексом
Наприклад на рис.10.19-10.20 показаний запит на вибірку документів що мають поле startdate рівним вказаній даті.

рис.10.19. Приклад використання Mango Query

рис.10.20. Приклад запиту за селектором
Для пришвидшення пошуку CouchDB надає механізми індексації. Вбудовані механізми передбачають створення індексу, який заповнюється після першого пошуку для пришвидшення виконання подальших запитів на пошук.
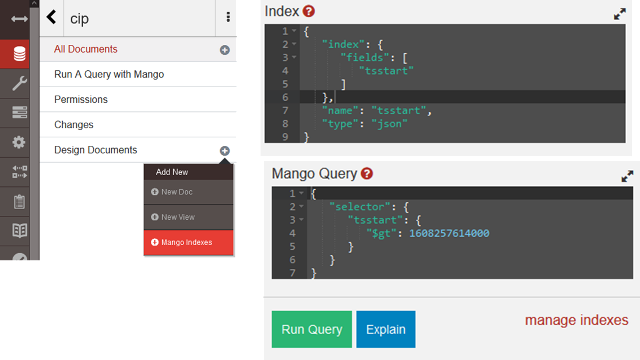
рис.10.21. Створення індексного документу
Є додаткові механізми індексованого пошуку, наприклад search indexes, які доступні в плагінах (в Cloudant вже вбудовані).
Для роботи с CouchDB в Node-RED доступні вузли Cloudant, які наразі включають в себе дещо обмежений функціонал, тому у більшості випадків варто працювати безпосередньо через REST API.
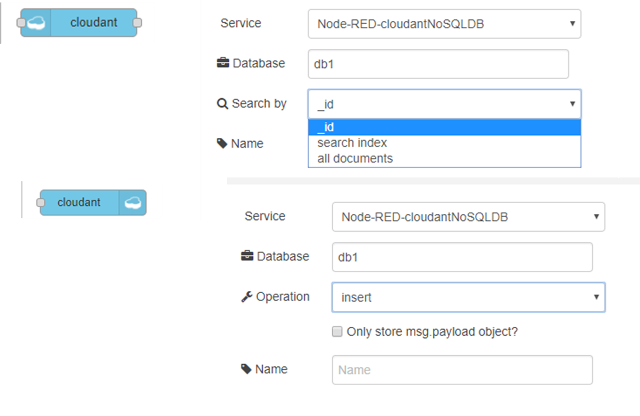
рис.10.22. Налаштування доступу з Node-RED
Альтернативою для CouchDB може стати MobgoDB для яких також є хмарний сервіс atlas https://www.mongodb.com/atlas/database , або Cassandra. На рис.10.23 показані основні відмінності СКБД CouchDB та MobgoDB .
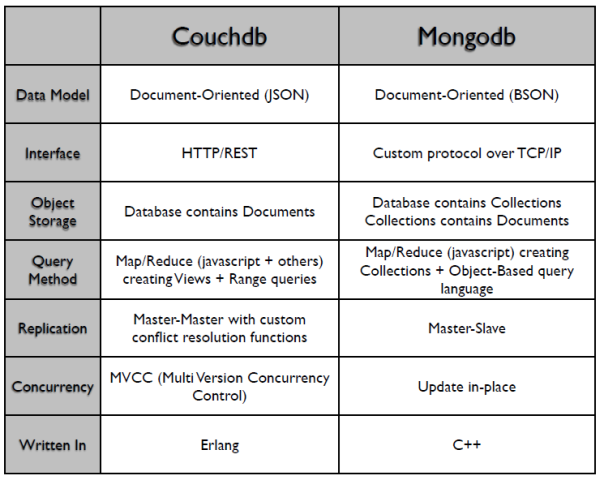
рис.10.23. Порівняння CouchDB з MongoDB
8.4. Cloud Object Storage
Коли необхідно зберігати об’єкти як атомарні одиниці варто використовувати спеціалізовані бази даних саме такого типу. Об’єктні сховища подібні до файлової системи, за відміною того, що про фізичне розміщення об’єкту користувачу невідоме, і воно може бути на різних носіях (рис.10.24). Доступ до них відбувається через API з вказівкою ідентифікатору.
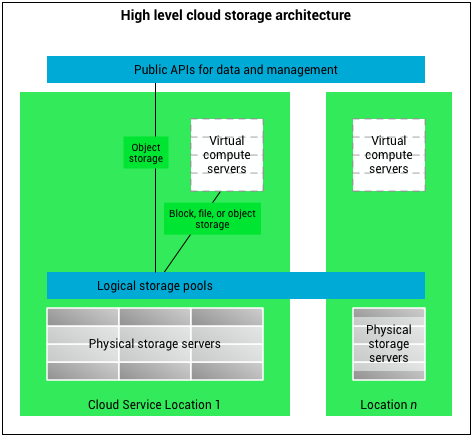
рис.10.24. Архітектура Cloud Storage
Прикладом такого хмарного сховища є IBM Cloud Object Storage (COS). Файли (об’єкти) в COS є неструктурованими даними (blob), тому можуть мати будь який формат. Доступ до них відбувається через REST API і керується через API-key. Об’єкти можуть бути дуже великими (>10Тб).
Організація даних відбувається через означення bucket (відро), яке є контейнером для об’єктів. Об’єкти в bucket аналогія файлів в папках. Дані зберігаються з використанням шифрування та хешуються. Для пришвидшення пошуку об’єкти тегуються.
Об’єктами COS можна користуватися як з сервісів IBM Cloud, так і поза ними. Для того, щоб мати можливість користуватися цими об’єктами поза межами IBM Cloud (через HTTP API) необхідно налаштувати доступ.
Для Node-RED існує готовий модуль інтеграції node-red-contrib-cos. Вузол cos get забезпечує доступ для читання. У налаштуваннях вказується Service credentials для екземпляра COS (рис.10.25) які копіюються з відповідного JSON файлу.

рис.10.25. Налаштування доступу до COS
8.5. Призначення аналітичних сервісів
У минулій лекції розглядалися сервіси зберігання даних у вигляді часових рядів. Але самі збережені дані не представляють цінності без їх обробки репрезентації. Дані можуть бути використані для машинного навчання та подальшого аналізу на предмет виявлення аномалій та їх причин, прогнозувати відмову устатковання за даними реального часу та історичними даними, робити повідомлення операторам та т.ін. Ці способи аналізу є предметом інших дисциплін. Більш простим способом є візуалізація даних, у цій лекції розглянемо саме ці можливості.
Використовуючи спеціалізовані клієнтські застосунки разом з Historian/TSDB, можна, наприклад, вирішувати такі завдання:
-
контролювати пристрій, щоб підтримувати його функціонування та визначати необхідність калібрування, ремонту чи заміни;
-
контролювати процес, набір устатковання, щоб змусити його працювати в рамках набору специфікацій процесу;
-
проводити моніторинг виробництва партії, порівнюючи її параметри з найкращою (“золотою”) партією;
-
контролювати якість продукції в межах можливостей процесу;
-
контролювати виробничу лінію для досягнення максимальної експлуатаційної ефективності та мінімальних витрат;
-
контролювати всі аспекти діяльності підприємства для оптимізації попиту та споживання ресурсів;
-
одночасно контролювати декілька однотипних об’єктів для порівняльного аналізу;
На рис. 12.1 показано приклад використання даних Historian для відображення статистичного розподілу 20-ти найчастіших тривог (типи показано кольором) для визначення їх причин.
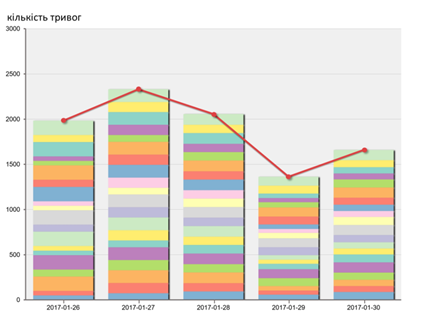
Рис. 11.1. Приклад використання клієнта Historian для аналізу тривог
А на рис. 12.2 показано приклад онлайн-звіту по тривогах, який дає змогу інженерам робити висновок щодо ефективності устатковання. У звіті показано тривоги в кінці зміни, найпопулярніші тривоги за кількістю, блоковані оператором тривоги та тривоги калібрування в кінці зміни, середній показник кількості тривог за зміну, розподіл частот тривог кожного типу. Натиснувши один із кольорових кружечків на “тепловій карті”, можна перенести користувача до звіту про вибраний тип тривоги, який попередньо фільтрується на потрібний день. Користувач може продовжувати поглиблення до тих пір, поки в кінцевому підсумку не з’являться вихідні сигнали тривоги та події, які можуть бути використані для аналізу першопричини та відображення відфільтрованих подій до, під час та після аварійної тривоги.
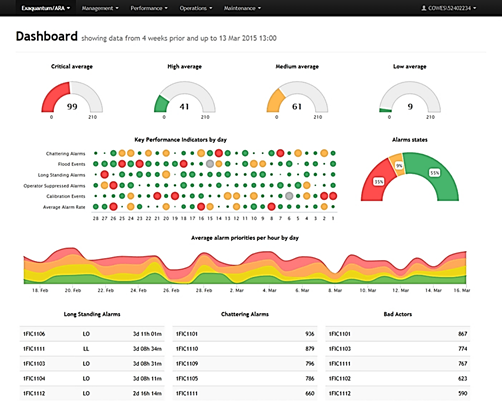
Рис. 11.2. Приклад використання клієнта Historian для аналізу причин тривог
Аналогічно можна використовувати різноманітні застосунки для підключення до різноманітних TSDB. На сьогодні для цього є багато програмних пакетів для керування звітами. Останнім часом в область інтегрованих систем керування заходять IT продукти, і для підсистем звітності це не є виключенням. Серед популярних пакунків варто виділити Grafana, який на сьогодні займає лідируючу позицію.
8.6. Grafana
Grafana - це програмне забезпечення для візуалізації та аналітики з відкритим кодом, яке дозволяє запитувати, візуалізувати, попереджати та досліджувати показники незалежно від того, де вони зберігаються.
Нижче розглянемо вбудовані можливості Grafana.
Джерела даних (Data sources)
Grafana підтримує багато різних джерел для зберігання даних часових рядів. Лише користувачі з роллю адміністратора можуть додавати джерела даних. Кожне джерело даних має конкретний редактор запитів (Query Editor), налаштований відповідно до функцій і можливостей, які надає джерело даних, оскільки, мова запитів і можливості кожного джерела даних дуже різняться. На одному дашбоарді (Dashboard) можна об’єднувати дані з різних джерел, проте кожна панель (panel) прив’язана до одного конкретного джерела даних.
Офіційно підтримуються такі джерела даних:
- Alertmanager
- AWS CloudWatch
- Azure Monitor
- Elasticsearch
- Google Cloud Monitoring
- Graphite
- InfluxDB
- Loki
- Microsoft SQL Server (MSSQL)
- MySQL
- OpenTSDB
- PostgreSQL
- Prometheus
- Jaeger
- Zipkin
- Tempo
- Testdata
Додатково джерела даних можна встановлювати як плагіни. За посиланням список підтримуваних плагінів-джерел даних.
Візуалізація даних
Панель (Panel) – це основний блок візуалізації в Grafana. Кожна панель має редактор запитів, особливості якого залежать від джерела даних, обраного на панелі. Існує широкий вибір стилів і варіантів форматування для кожної панелі. Їх можна перетягувати та переміщувати на дашбоарді. Grafana пропонує різноманітні типи візуалізації для різних випадків використання.
Графіки та діаграми
Time series – типова візуалізація у вигляді графіка.
State timeline – відображення дискретних змін стану з часом. Кожне поле (field) або серія (series) відображається як унікальна горизонтальна смуга. Ця панель добре працює із станами типів String i Boolean, але також може використовуватися з часовими рядами. При використанні з часовими рядами пороги використовуються для перетворення числових значень в області дискретного стану.
Status history – періодичні стани з часом. Кожне поле або серія відображаються як горизонтальний рядок. Поле відображаються та центруються навколо кожного значення.
Гістограма показує будь-які категоріальні дані.
Гістограма обчислює і показує розподіл значень на гістограмі.
Теплова карта візуалізує дані у двох вимірах, які зазвичай використовуються для визначення масштабу явища.
Секторна діаграма зазвичай використовується там, де важлива пропорційність.
Explorer
Перед побудовою панелей dashboard можна скористатися функцією Explore, за допомогою якої можна досліджувати дані за допомогою спеціальних запитів та динамічного відновлення. Це дає можливість зосередитися на формування запитів та аналізу отриманих результатів. Explore відображає результати як у вигляді графіку, так і таблиці, що дозволяє одночасно бачити тенденції в даних та більше деталей.
Розділений вигляд забезпечує простий спосіб порівняти графіки та таблиці поруч або переглянути спільні дані на одній сторінці. Можна вибрати інше джерело даних для нового запиту, яке, наприклад, дозволяє порівняти один і той же запит для двох різних серверів або порівняти проміжне середовище із виробничим середовищем. У розділеному поданні підбирачі часу для обох панелей можна пов’язати (якщо змінити одну, зміниться і інша), натиснувши одну з кнопок синхронізації часу, прикріплену до вибору часу. Пов’язування часових інструментів допомагає синхронізувати час початку та закінчення запитів розділеного подання.
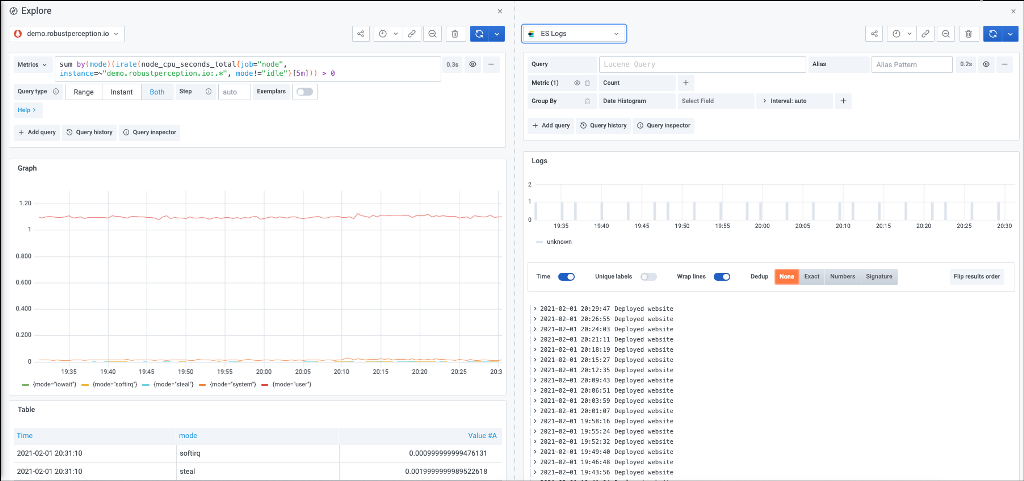
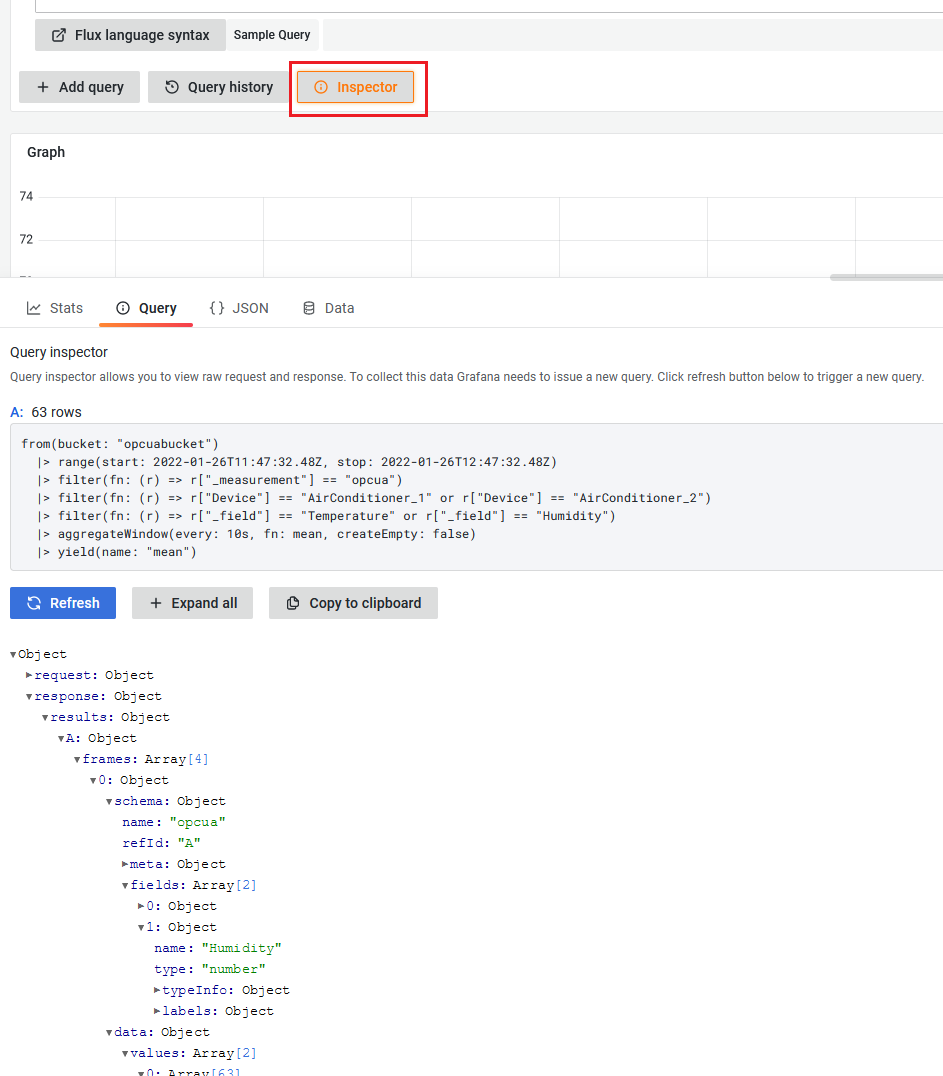
Explore дозволяє досліджувати запити та відповіді на них, а також статистику запитів за допомогою **інспектора запитів **(Query inspector). Інспектор надає можливість перевіряти сирі дані, експортувати ці дані в csv-форматі, експортувати результати запиту журналу у форматі TXT та переглядати запит на запит. Інтерфейс інспектора включає наступні вкладки:
Вкладка Stats – показує, скільки часу виконується запит та кількість даних, що він повертає.
Вкладка Query – показує запит, який відправляє Grafana до джерела даних.
Вкладка JSON – дозволяє переглядати та копіювати дані в JSON форматі.
Вкладка Data – показує сирі дані, повернуті запитом.
Вкладка Error – показує помилку. Відображається лише тоді, коли запит повертає помилку.
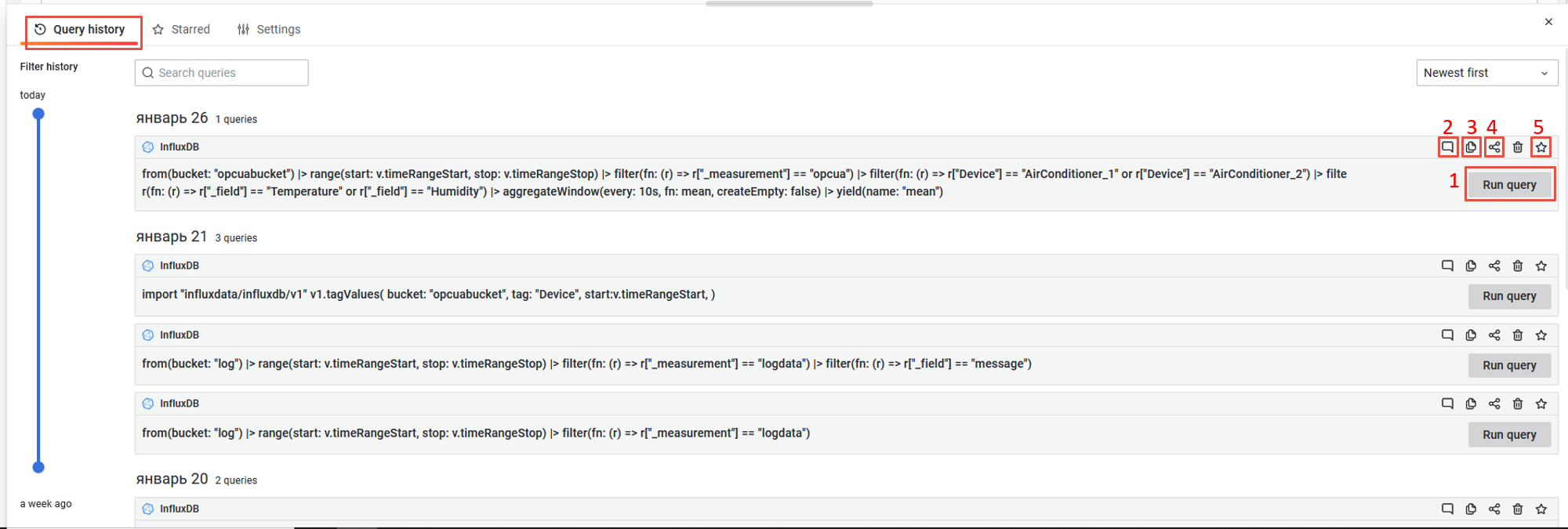
Також Expore надає можливість переглядати історію запитів. Для кожного запиту з історії можна виконати:
- Виконати запит
- Створити та/або відредагувати коментар
- Скопіювати запит у буфер обміну
- Скопіювати в буфер обміну скорочене посилання із запитом
- Відмітити запит як улюблений (Star Query)
Попередження (Alerts)
Якщо ви використовуєте попередження Grafana, тоді ви можете надсилати сповіщення через багато різних відправників сповіщень, включаючи PagerDuty, SMS, електронну пошту, VictorOps, OpsGenie або Slack.
Якщо ви віддаєте перевагу іншим каналам зв’язку попереджувальні хуки (Alert hooks) дозволяють створювати різні сповіщувачі з використанням фрагментів коду. Візуально визначте правила попередження для найважливіших показників.
Анотації (Annotations)
Анотуйте графіки до насичених подій з різних джерел даних. Наведіть курсор на події, щоб переглянути повні метадані та теги подій.
Ця функція, яка відображається як графічний маркер у Grafana, корисна для кореляції даних на випадок, якщо щось піде не так. Ви можете створювати анотації вручну - просто клацніть на графіку та вводьте текст, натискаючи клавішу Control, або ви можете отримувати дані з будь-якого джерела даних.
Змінні інформаційних панелей (Dashboard variables)
Змінні шаблону дозволяють створювати інформаційні панелі, які можна використовувати повторно для багатьох різних випадків використання. Ці шаблони не мають жорсткого кодування, тому, наприклад, якщо у вас є робочий і тестовий сервери, ви можете використовувати одну і ту ж інформаційну панель для обох.
Шаблонування дозволяє детально переглянути ваші дані, скажімо, від усіх даних до даних Північної Америки, до даних Техасу та не тільки. Ви також можете ділитися цими інформаційними панелями між командами у вашій організації - або якщо ви створюєте чудовий шаблон інформаційної панелі для популярного джерела даних, ви можете внести його в цілу спільноту для налаштування та використання.
Конфігурування Grafana
Якщо ви адміністратор Grafana, то вам захочеться досконально ознайомитися з Параметри конфігурації Grafana та Grafana CLI.
Конфігурація охоплює як файли конфігурації, так і змінні середовища. Ви можете встановити порти за замовчуванням, рівні реєстрації, IP-адреси електронної пошти, безпеку тощо.
Імпортування інформаційних панелей та плагіни (Import dashboards and plugins)
Відкрийте для себе сотні інформаційних панелей та плагінів в офіційній бібліотеці. Завдяки пристрасті та імпульсу членів спільноти щотижня додаються нові.
Автентифікація
Grafana підтримує різні методи автентифікації, такі як LDAP та OAuth, і дозволяє зіставляти користувачів із організаціями. Для отримання додаткової інформації зверніться до Огляд автентифікації користувача.
У Grafana Enterprise ви також можете зіставити користувачів із командами: Якщо ваша компанія має власну систему автентифікації, Grafana дозволяє вам зіставити команди у вашій внутрішній системі з командами в Grafana. Таким чином, ви можете автоматично надати людям доступ до інформаційних панелей, призначених для їхніх команд.
Зверніться до розділу Grafana Enterprise для отримання додаткової інформації.
Налаштування сценаріїв розгортання (Provisioning)
Незважаючи на те, що створення єдиної інформаційної панелі модна через “drag and drop”, досвідчені користувачі, які потребують багатьох інформаційних панелей, захочуть автоматизувати налаштування за допомогою сценарію. Ви можете писати будь-що на сценарії Grafana.
Наприклад, якщо ви створюєте новий кластер Kubernetes, ви також можете автоматично створити Grafana за допомогою скрипта, який має правильний сервер, IP-адресу та джерела даних, попередньо встановлені та заблоковані, щоб користувачі не могли їх змінити. Це також спосіб отримати контроль над багатьма інформаційними панелями.
Для отримання додаткової інформації зверніться до Provisioning .
Дозволи (Permissions)
Коли в організаціях є одна Grafana та кілька команд, вони часто хочуть мати можливість тримати речі окремо та спільно використовувати інформаційні панелі. Ви можете створити групу користувачів, а потім встановити дозволи для папок, інформаційних панелей і аж до рівня джерела даних, якщо ви використовуєте Grafana Enterprise.
Grafana Cloud
Grafana Cloud - це високодоступна, швидка, повністю керована платформа реєстрації та метрики OpenSaaS. Там все, що вам подобається в Grafana, але Grafana Labs пропонує це для вас і вирішує всі головні болі.
Дізнайтеся більше про Grafana Cloud або спробуйте швидкий старт хосту Grafana Cloud Linux.
Grafana Enterprise
Grafana Enterprise - комерційне видання Grafana, що включає додаткові функції, яких немає у версії з відкритим кодом.
Спираючись на все, що ви вже знаєте і любите про Grafana, Grafana Enterprise додає корпоративні джерела даних, розширені параметри автентифікації, додаткові засоби контролю дозволів, підтримку 24x7x365 та навчання від основної команди Grafana.
Дізнайтеся більше про Grafana Enterprise. Щоб придбати Enterprise або отримати пробну ліцензію, зверніться до Grafana Labs Команда продажів.
Запитання для самоперевірки
- Для чого використовуються сховища в інфраструктурі IIoT? На яких засобах вони можуть бути розміщені?
- Наведіть приклади використання реляційних хмарних СКБД в структурі інтегрованої системи керування.
- Поясніть що таке NoSQL СКБД.
- Поясніть що таке документ-орієнтована БД.
- Як дані організовані в CouchDB?
- Поясніть як функціонують REST API запити на створення та доступ до БД та документів.
- Як в CouchDB організована реплікація?
- Як в CouchDB організований пошук документів за їх змістом?
- Розкажіть про механізми індексації документів в CouchDB.
- Як можна користуватися сервісами CouchDB в Node-RED?
- Розкажіть про призначення сховищ Cloud Object Storage. Наведіть приклад їх використання. в інтегрованих системах керування та IIoT
| <- до лекцій | на основну сторінку курсу |
|---|---|