Як почати з Grafana
Ця тема допоможе вам розпочати роботу з Grafana та створити свою першу інформаційну панель.
Примітка: Grafana також пропонує безкоштовний обліковий запис у Grafana Cloud, щоб допомогти розпочати роботу ще простіше та швидше. Ви можете встановити Grafana для самостійного розміщення або отримати безкоштовний обліковий запис Grafana Cloud.
Step 1: Встановлення Grafana
Grafana може бути встановлена на багатьох різних операційних системах. Список мінімальних вимог до обладнання та програмного забезпечення, а також інструкції щодо встановлення Grafana див. У розділі Встановити Grafana.
Step 2: Log in
Щоб увійти в Grafana вперше:
- Відкрийте веб-браузер і перейдіть на http://localhost:3000/. HTTP-порт за промовчанням, який слухає Grafana, -
3000, якщо ви не налаштували інший порт. - На сторінці входу введіть
adminдля імені користувача та пароля. - Клацніть Log In. Якщо вхід буде успішним, ви побачите запит на зміну пароля.
- Клацніть OK у запиті, а потім змініть пароль.
Примітка: Настійно рекомендуємо дотримуватися найкращих практик Grafana та змінити пароль адміністратора за замовчуванням. Не забудьте записати свої облікові дані!
Step 3: Створення dashboard
Щоб створити свою першу інформаційну панель:
- Клацніть піктограму + на лівій панелі, виберіть Create Dashboard, а потім натисніть Add an empty panel.
- У вікні New Dashboard/Edit Panel перейдіть на вкладку Query.
- Налаштуйте свій запит, вибравши
-- Grafana --у data source selector. Це генерує інформаційну панель Random Walk. - Клацніть піктограму Save у верхньому правому куті екрана, щоб зберегти інформаційну панель.
- Додайте описову назву, а потім натисніть **Save **.
Вітаємо! Ви створили свою першу інформаційну панель, і вона відображає результати.
Наступні кроки
Продовжуйте експериментувати зі створеним, спробуйте дослідити робочий процес або іншу функцію візуалізації. Зверніться до Джерела даних, щоб отримати список підтримуваних джерел даних та інструкції щодо додавання джерела даних. Наступні теми будуть вам цікаві:
Admins
Наступні теми цікавлять користувачів адміністратора сервера Grafana:
Введеня в часові ряди
Уявіть, ви хотіли знати, як температура на вулиці змінюється протягом дня. Раз на годину ви перевіряли термометр і записували час разом із поточною температурою. Через деякий час у вас вийде щось подібне:
| Time | Value |
|---|---|
| 09:00 | 24°C |
| 10:00 | 26°C |
| 11:00 | 27°C |
Такі дані про температуру є одним із прикладів того, що ми називаємо часовим рядом (time series) - послідовністю вимірювань, упорядкованою у часі. Кожен рядок у таблиці представляє одне окреме вимірювання в певний час.
Таблиці корисні, коли ви хочете визначити окремі вимірювання, але ускладнюєте бачення загальної картини. Більш поширеною візуалізацією для часових рядів є графік, який замість цього розміщує кожне вимірювання вздовж осі часу. Візуальні подання, такі як графік, полегшують виявлення шаблонів та особливостей даних, які в іншому випадку було б важко побачити.
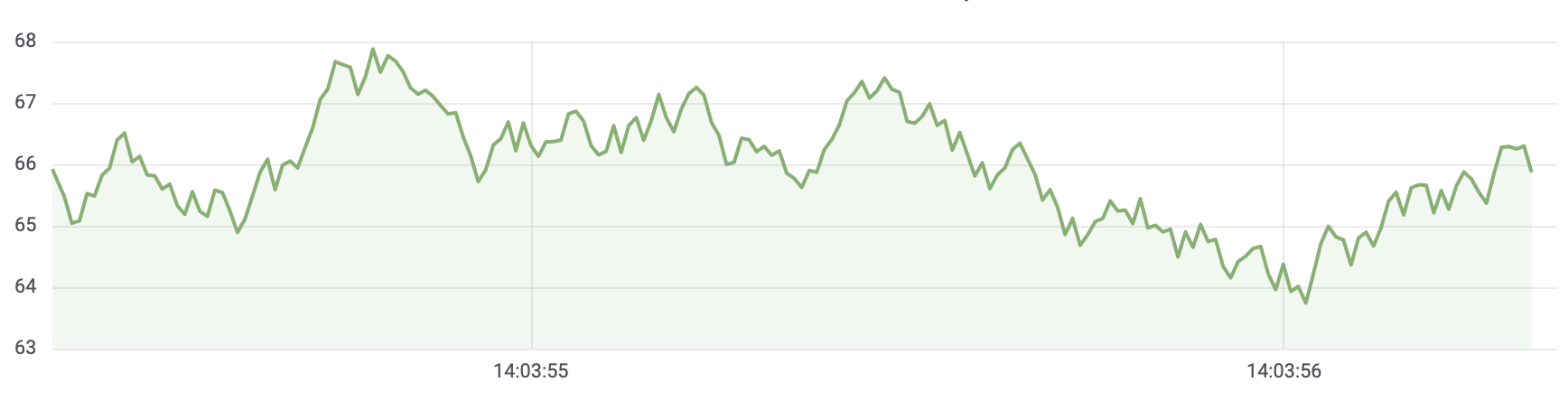
Дані про температуру, як у прикладі, далеко не єдиний приклад часового ряду. Іншими прикладами часових рядів є:
- Використання центрального процесора та пам’яті
- Дані датчика
- Індекс фондового ринку
Хоча кожен з цих прикладів є послідовностями хронологічно упорядкованих вимірювань, вони також мають інші атрибути:
- Нові дані додаються в кінці, через рівні проміжки часу, наприклад, щогодини о 09:00, 10:00, 11:00 тощо.
- Вимірювання рідко оновлюються після їх додавання - наприклад, температура вчора не змінюється.
Часові ряди є потужними. Вони допомагають зрозуміти минуле, дозволяючи аналізувати стан системи в будь-який момент часу. Часові ряди можуть сказати вам, що сервер вийшов з ладу через кілька хвилин після того, як вільний простір на диску зменшився до нуля.
Часові ряди також можуть допомогти вам передбачити майбутнє, розкриваючи тенденції у ваших даних. Якщо кількість зареєстрованих користувачів щомісяця збільшується на 4% протягом останніх кількох місяців, ви можете передбачити, наскільки великою буде ваша база користувачів наприкінці року.
Деякі часові ряди мають закономірності, що повторюються протягом відомого періоду. Наприклад, температура, як правило, вища вдень, перш ніж вона опуститься вночі. Визначивши ці періодичні, або сезонні, часові ряди, ви можете робити впевнені прогнози щодо наступного періоду. Якщо ми знаємо, що завантаження системи досягає максимуму щодня близько 18:00, ми можемо додати більше машин безпосередньо перед цим.
Агрегування часових рядів (Aggregating)
Залежно від того, що ви вимірюєте, дані можуть сильно відрізнятися. Що робити, якщо ви хочете порівняти періоди, довші за інтервал між вимірами? Якщо ви вимірювали температуру раз на годину, у вас вийшло б 24 точки даних на день. Щоб порівняти температуру в серпні за ці роки, вам потрібно було б об’єднати 31 раз по 24 точки даних в одну.
Комбінування колекції вимірювань називається агрегація. Існує кілька способів агрегування даних часових рядів. Ось кілька загальних:
- Average повертає суму всіх значень, поділену на загальну кількість значень.
- Min та Max повертають найменше та найбільше значення у колекції.
- Sum повертає суму всіх значень у колекції.
- Count повертає кількість значень у колекції.
Наприклад, за допомогою агрегування даних за місяць можна визначити, що серпень 2017 року в середньому був теплішим, ніж роком раніше. Натомість, щоб побачити, у якому місяці була найвища температура, ви порівняли би максимальну температуру для кожного місяця.
Спосіб узагальнення даних часових рядів є важливим рішенням і залежить від історії, яку ви хочете розповісти разом із своїми даними. Зазвичай використовують різні агрегації для візуалізації одних і тих же даних часових рядів різними способами.
Часові ряди та моніторинг
В ІТ-галузі часто збираються дані часових рядів для моніторингу таких речей, як інфраструктура, обладнання або події додатків. Дані часових рядів, що генеруються машиною, зазвичай збираються з короткими інтервалами, що дозволяє реагувати на будь-які несподівані зміни через кілька моментів після їх виникнення. Як наслідок, дані накопичуються швидкими темпами, тому життєво важливим є спосіб ефективного зберігання та запиту даних. Як результат, бази даних, оптимізовані для даних часових рядів, за останні роки зафіксували зростання популярності.
Time series databases
База даних часових рядів (TSDB) - це база даних, явно розроблена для даних часових рядів. Хоча для зберігання вимірювань можна використовувати будь-яку звичайну базу даних, TSDB постачає деякі корисні оптимізації.
Сучасні бази даних часових рядів використовують переваги того, що вимірювання лише колись додаються і рідко оновлюються або видаляються. Наприклад, мітки часу для кожного вимірювання змінюються дуже мало з часом, що призводить до збереження надлишкових даних.
Подивіться на цю послідовність часових міток Unix:
1572524345, 1572524375, 1572524404, 1572524434, 1572524464
Переглядаючи ці мітки часу, всі вони починаються з 1572524, що призводить до поганого використання дискового простору. Натомість ми могли б зберігати кожну наступну мітку часу як різницю, або delta, від першої:
1572524345, +30, +29, +30, +30
Ми навіть могли зробити крок далі, обчисливши дельти цих дельт:
1572524345, +30, -1, +1, +0
Якщо вимірювання проводяться через рівні проміжки часу, більшість цих дельт-дельт становитимуть 0. Через такі оптимізації TSDB використовують значно менше місця, ніж інші бази даних.
Ще однією особливістю TSDB є можливість фільтрування вимірювань за допомогою тегів. Кожна точка даних позначена тегом, що додає контекстну інформацію, наприклад, де проводилось вимірювання. Ось приклад формату даних InfluxDB, який демонструє, як зберігається кожне вимірювання.
Ось деякі з TSDB, які підтримує Grafana:
-
weather,location=us-midwest temperature=82 1465839830100400200 | -------------------- -------------- | | | | | | | | | +-----------+--------+-+---------+-+---------+ |measurement|,tag_set| |field_set| |timestamp| +-----------+--------+-+---------+-+---------+
Збирання даних часових рядів
Тепер, коли у нас є де зберігати наші часові ряди, як насправді збирати вимірювання? Для збору даних часових рядів ви зазвичай встановлюєте колектор на пристрій, машину або екземпляр, який ви хочете контролювати. Деякі колектори створені з урахуванням конкретної бази даних, а деякі підтримують різні вихідні напрямки.
Ось кілька прикладів колекторів:
Колектор або штовхає дані до бази даних, або дозволяє базі даних витягувати дані з неї. Обидва методи мають свої плюси і мінуси:
| Pros | Cons | |
|---|---|---|
| Push | Легше тиражувати (реплікувати) дані в декілька пунктів призначення. | TSDB не має контролю над тим, скільки даних надсилається. |
| Pull | Кращий контроль над тим, скільки даних надходить, та їх достовірність. | Брандмауери, VPN або балансири навантаження можуть ускладнити доступ до агентів. |
Оскільки було б неефективно записувати кожен вимір у базу даних, колектори попередньо агрегують дані та регулярно записують у базу даних часових рядів.
Розмірності часових рядів (Time series dimensions)
У Вступі до часових рядів були введені поняття міток та тегів:
Ще однією особливістю TSDB є можливість фільтрувати вимірювання за допомогою тегів. Кожна точка даних позначена тегом, який додає контекстну інформацію, наприклад, де проводилось вимірювання.
У даних часових рядів часто містяться більше ніж один ряд, і являють собою набір великої кількості часових рядів. Багато джерел даних Grafana підтримують такий тип даних.
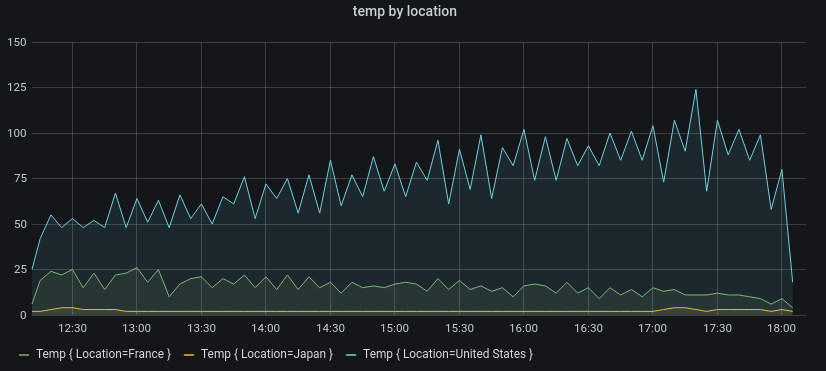
Поширений випадок - це видача одного запиту на вимірювання з одним або кількома додатковими властивостями як розмірності (dimensions). Наприклад, запит на вимірювання температури разом із властивістю розташування. У цьому випадку з цього єдиного запиту повертається кілька послідовностей (рядів), і кожна послідовність в якості розмірності має унікальне розташування .
Для ідентифікації унікальних рядів у наборі часових рядів Grafana зберігає розмірності у мітках (labels).
Мітки (Labels)
Time series databases (TSDBs) usually natively support dimensionality. Prometheus also stores dimensions in labels. In TSDBs such as Graphite or OpenTSDB the term tags is used instead.
In table databases such SQL, these dimensions are generally the GROUP BY parameters of a query.
Кожен часовий ряд у Grafana необов’язково має мітки. Мітки встановлюються як пара ключів/значень для визначення розмірності. Прикладом міток може бути {location = us} або {country = us, state = ma, city = boston}. У межа набору часових рядів поєднання його назви та міток ідентифікує кожен ряд. Наприклад, temperature {country=us,state=ma,city=boston}.
Різні джерела даних часових рядів мають розмірності, що зберігаються у власних пам’ятках, або загальні схеми зберігання, які дозволяють витягувати дані у розмірності.
Бази даних часових рядів (TSDB), як правило, підтримують розмірності (dimensionality). Prometheus також зберігає розміри в мітках. У TSDB, таких як Graphite або OpenTSDB, замість цього використовується термін теги.
У таблицях баз даних, таких як SQL, ці розміри, як правило, є параметрами “GROUP BY” запиту.
Кілька розмірностей у форматі таблиці
У базах даних SQL або подібних до SQL, які повертають відповіді таблиці, додаткові розмірності, як правило є стовпцями в таблиці відповідей запиту.
Єдина розмірність
Наприклад, розглянемо такий запит, як:
SELECT BUCKET(StartTime, 1h), AVG(Temperature) AS Temp, Location FROM T
GROUP BY BUCKET(StartTime, 1h), Location
ORDER BY time asc
Може повернути таблицю з трьома стовпцями, кожна з яких відповідно має типи даних, number та string.
| StartTime | Temp | Location |
|---|---|---|
| 09:00 | 24 | LGA |
| 09:00 | 20 | BOS |
| 10:00 | 26 | LGA |
| 10:00 | 22 | BOS |
Формат таблиці - це long відформатований часовий ряд, який також називають tall. Він має повторювані позначки часу та повторювані значення в Location. У цьому випадку у нас є два часові ряди в наборі, які будуть ідентифіковані як Temp {Location = LGA} і Temp {Location = BOS}.
Окремі часові ряди з набору витягуються за допомогою набраного за часом стовпця StartTime як індексу часу часового ряду, числового набраного стовпця Temp як назви ряду, а також імені та значень наведеного рядка Location для створення міток, наприклад Location = LGA.
Кілька розмірностей
Якщо запит оновлено для вибору та групування більш ніж за одною колонкою типу string, наприклад, GROUP BY BUCKET (StartTime, 1h), Location, Sensor, тоді додається додаткова розмірнсть:
| StartTime | Temp | Location | Sensor |
|---|---|---|---|
| 09:00 | 24 | LGA | A |
| 09:00 | 24.1 | LGA | B |
| 09:00 | 20 | BOS | A |
| 09:00 | 20.2 | BOS | B |
| 10:00 | 26 | LGA | A |
| 10:00 | 26.1 | LGA | B |
| 10:00 | 22 | BOS | A |
| 10:00 | 22.2 | BOS | B |
У цьому випадку мітки, що представляють розміри, матимуть два ключі на основі двох набраних рядків стовпців Location і Sensor. Ці дані дають чотири ряди: Temp {Location = LGA, Sensor = A}, Temp {Location = LGA, Sensor = B}, Temp {Location = BOS, Sensor = A} і Temp {Location = BOS, датчик = B} .
Примітка: Наразі більше одного виміру підтримується лише в запитах журналів служби Azure Monitor, починаючи з версії 7.1.
Примітка: Кілька вимірів не підтримуються таким чином, щоб зіставляти декілька сповіщень у Grafana, а навпаки, вони розглядаються як кілька умов для одного попередження. Див. Документацію щодо створення сповіщень із кількома рядами.
Кілька значень
У випадку джерел даних, схожих на SQL, можна вибрати більше одного числового стовпця з додатковими рядковими стовпцями або без них, які будуть використовуватися як розмірності. Наприклад, AVG (Temperature) AS AvgTemp, MAX (Temperature) AS MaxTemp. Це в поєднанні з кількома вимірами може призвести до багатьох рядів. Наразі вибір кількох значень призначений лише для візуалізації.
Додаткову технічну інформацію про табличні формати часових рядів та спосіб вилучення розмірностей можна знайти в документація розробника щодо фреймів даних як часових рядів.
Джерела даних (Data sources)
Grafana підтримує багато різних сховищ даних для ваших часових рядів (джерело даних). Зверніться до Додати джерело даних, щоб отримати вказівки щодо того, як додати джерело даних до Grafana. Лише користувачі з роллю адміністратора організації можуть додавати джерела даних.
Формування запитів (Querying)
Кожне джерело даних має спеціальний редактор запитів, який налаштований на функції та можливості, які надає конкретне джерело даних. Мова запитів та можливості кожного джерела даних, очевидно, дуже різні. Ви можете об’єднати дані з декількох джерел даних на одній інформаційній панелі, але кожна панель прив’язана до певного джерела даних, яке належить певній Організації.
Підтримувані ресурси
Офіційно підтримуються такі джерела даних:
- AWS CloudWatch
- Azure Monitor
- Elasticsearch
- Google Cloud Monitoring
- Graphite
- InfluxDB
- Loki
- Microsoft SQL Server (MSSQL)
- MySQL
- OpenTSDB
- PostgreSQL
- Prometheus
- Jaeger
- Zipkin
- Tempo
- Testdata
На додаток до джерел даних, які ви налаштували у своїй Grafana, доступні три спеціальні джерела даних:
- Grafana - A built-in data source that generates random walk data. Useful for testing visualizations and running experiments. Вбудоване джерело даних, яке генерує випадкові дані. Корисно для тестування візуалізації та запуску експериментів.
- Mixed - Виберіть це для запиту декількох джерел даних на одній панелі. Коли вибрано це джерело даних, Grafana дозволяє вибрати джерело даних для кожного нового доданого запиту.
- Перший запит використовуватиме джерело даних, яке було вибрано до вашого вибору Mixed.
- Ви не можете змінити існуючий запит, щоб використовувати Mixed Data Source.
- Grafana Play example: Mixed data sources
- Dashboard - Виберіть це, щоб використовувати набір результатів з іншої панелі на тій же інформаційній панелі.
З Grafana 3.0 ви можете встановлювати джерела даних як плагіни. Перегляньте Grafana.com/plugins, щоб отримати більше джерел даних.
Вступ до гістограм та теплових карт
Гістограма - це графічне зображення розподілу числових даних. Він групує значення у сегменти (іноді їх також називають bins), а потім підраховує, скільки значень потрапляє в кожен сегмент.
Замість того, щоб відображати фактичні значення, гістограми зображують сегменти. Кожен стовпчик являє собою сегмент, а висота стовпчика - частоту (наприклад, кількість) значень, що потрапили в інтервал цього сегмента.
Приклад гістрограми
Ця гістограма показує розподіл значень пари часових рядів. Ви можете легко побачити, що більшість значень припадає на 240-300, а пік - 260-280.
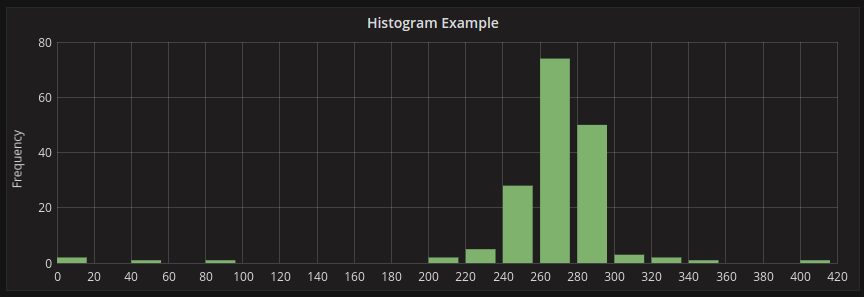
Гістограми розглядають лише розподіл значень протягом певного діапазону часу. Проблема гістограм полягає в тому, що ви не можете побачити жодних тенденцій або змін у розподілі з часом. Тут стають корисними теплові карти .
Теплові карти (heatmap)
Теплова карта схожа на гістограму, але з часом, коли кожен зріз часу представляє свою власну гістограму. Замість того, щоб використовувати висоту стовпчика як зображення частоти, він використовує комірки та забарвлює клітинку пропорційно кількості значень у сегменті.
У цьому прикладі ви можете чітко побачити, які значенні є більш поширеними та як вони змінюються з часом.
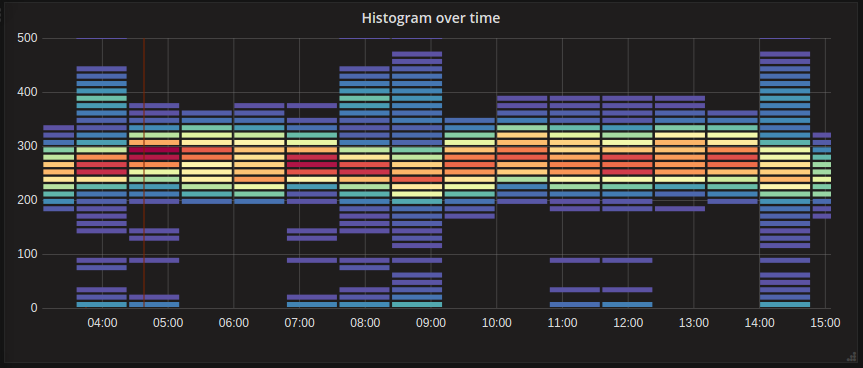
Pre-bucketed data
Існує ряд джерел даних, що підтримують гістограму з часом, наприклад Elasticsearch (за допомогою агрегації сегментів Гістограми) або Prometheus (з гістограмою метричного типу та опцією Format as встановлено для Heatmap). Але загалом можна використовувати будь-яке джерело даних, якщо воно відповідає вимогам: повертає ряди з іменами, що представляють зв’язані сегменти, або повертає ряди, відсортовані за прив’язаними у порядку зростання.
Сирі дані проти агрегованих
Якщо ви використовуєте теплову карту зі звичайними даними часових рядів (не попередньо згрупованими), важливо мати на увазі, що ваші дані часто вже агрегуються вашим серверним інтерфейсом часових рядів. Більшість запитів часових рядів не повертають необроблені зразкові дані, але включають групу за часовим інтервалом або обмеженням maxDataPoints у поєднанні з функцією агрегування (зазвичай average).
Це все залежить від часового діапазону вашого запиту, звичайно. Але важливим моментом є знання того, що сегментація гістограми, яку виконує Grafana , може здійснюватися на вже агрегованих та усереднених даних. Щоб отримати більш точні теплові карти, краще робити сегментування під час збору метрики або зберігати дані в Elasticsearch або в іншому джерелі даних, яке підтримує сегментування гістограм на необроблених даних.
Якщо ви видалите або опустите групування за часом (або піднімете maxDataPoints) у вашому запиті, щоб повернути більше точок даних, ваша теплова карта буде більш точною, але це також може бути дуже обтяженим процесором та пам’яттю для вашого браузера і може призвести до зависання та збоїв, якщо число точок даних стає необґрунтовано великим.
Введення у взірець (exemplar )
Візрець- це конкретне трасування, що представляє повторний зразок даних у заданому інтервалі часу. Це допомагає вам ідентифікувати метадані вищої потужності з конкретних подій у даних часових рядів.
Припустимо, на веб-сайті вашої компанії спостерігається різкий обсяг трафіку. Хоча більше восьмидесяти відсотків користувачів можуть отримати доступ до веб-сайту менш ніж за дві секунди, у деяких користувачів час відгуку перевищує звичайний, що призводить до поганого користувацького досвіду
Щоб визначити фактори, що сприяють затримці, потрібно порівняти трасування для швидкої реакції та трасування для повільної реакції. Враховуючи величезний обсяг даних у типовому виробничому середовищі, це буде надзвичайно трудомістким зусиллям.
Використовуйте взірці, щоб допомогти відокремити проблеми у розподілі даних, визначивши траси запитів, що демонструють високу затримку протягом певного інтервалу часу. Як тільки локалізуєте проблему затримки на декількох зразкових трасах, ви можете поєднати її з додатковою системною інформацією або властивостями розташування, щоб швидше провести аналіз першопричини, що призведе до швидкого вирішення проблем із продуктивністю.
Підтримка зразків доступна лише для джерела даних Prometheus. Після того, як ви ввімкнете цю функцію, типові дані доступні за замовчуванням. Для отримання додаткової інформації про конфігурацію взірців та про те, як увімкнути взірці, зверніться до налаштування візрців у джерелі даних Prometheus.
Grafana показує взірці поряд із метрикою у поданні “Explore” та на інформаційних панелях. Кожен взірець відображається як виділена зірка. Ви можете навести курсор на приклад, щоб переглянути унікальний traceID, який є комбінацією пари значень ключа. Для подальшого дослідження натисніть синю кнопку поруч із властивістю traceID.
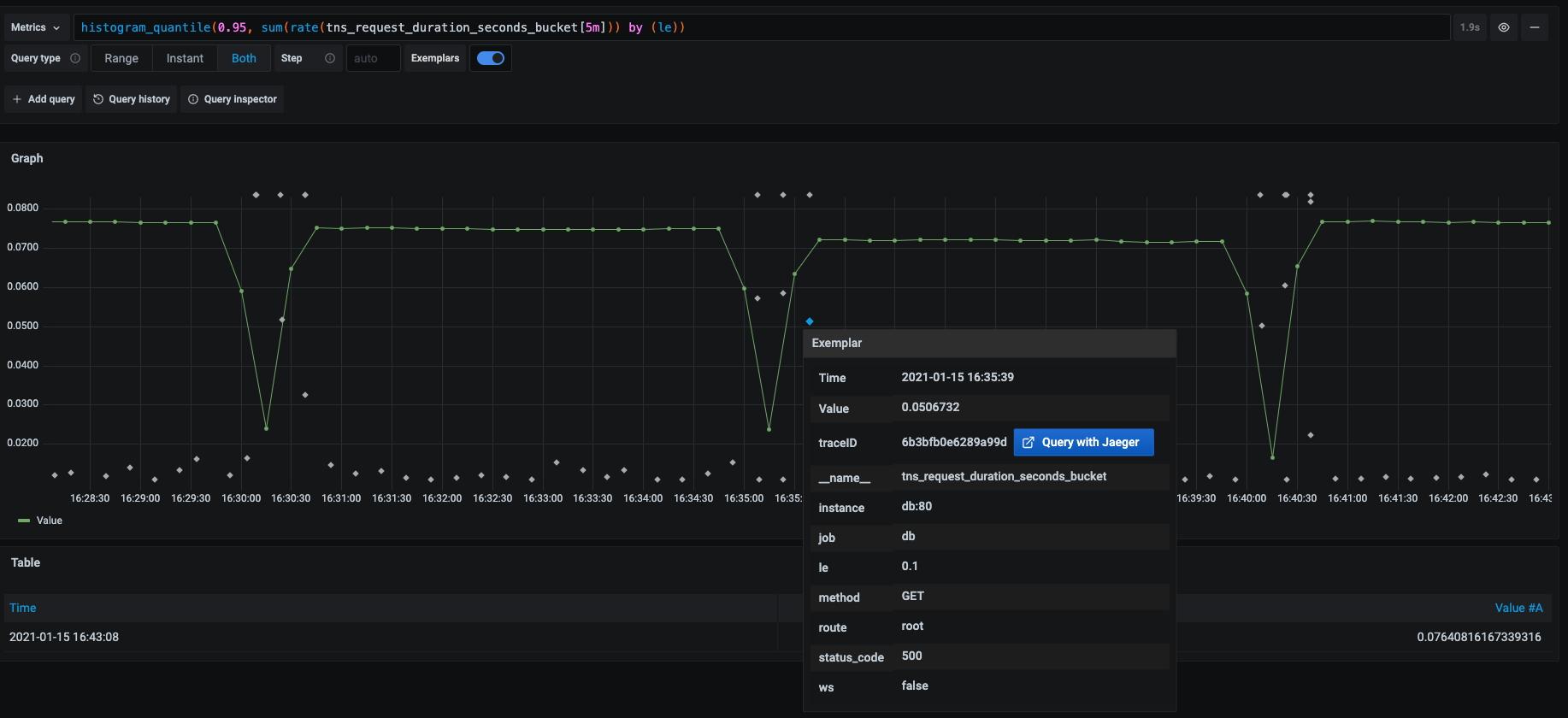
#####
Глосарій
У цій темі перелічені слова та скорочення, які зазвичай використовуються в документації та спільноті Grafana.
| Eng | Ukr | Пояснення |
|---|---|---|
| Dashboard | Приладова панель, Інформаційна панель | Набір з однієї або декількох панелей, організованих та розташованих в один або кілька рядків, що забезпечують короткий огляд пов’язаної інформації. |
| Data source | Джерело даних | Файл, база даних або сервіс, що надає дані. Grafana підтримує кілька джерел даних за замовчуванням, і може бути розширена для підтримки додаткових джерел даних за допомогою плагінів. |
| Exemplar | Взірець | Взірець є будь-якими даними, які служать детальним прикладом одного із спостережень, зведених у метрику. Візрець містить спостережуване значення разом із необов’язковою міткою часу та довільними мітками, які зазвичай використовуються для посилання на трасування. |
| Explore | Дослідження | Дослідження дозволяє користувачеві зосередитися на побудові запиту. Користувачі можуть уточнити запит, щоб повернути очікувані показники перед створенням приладової панелі. Для отримання додаткової інформації зверніться до теми Explore |
| Export/Import dashboard | Export/Import dashboard | Grafana включає можливість експортувати ваші інформаційні панелі у файл, що містить JSON. Учасники спільноти інколи діляться своїми створеними інформаційними панелями на сторінці Графічних інформаційних панелей. Інформаційні панелі, раніше експортовані або знайдені на цьому веб-сайті, можуть бути імпортовані іншими користувачами. |
| Exporter | Експортер | Експортер переводить дані, що надходять з джерела даних, у формат, який Prometheus може засвоїти. |
| Integration (Grafana Cloud) | Integration (Grafana Cloud) | Кожна інтеграція в Grafana Cloud використовує хмарний агент для підключення джерела даних до Grafana Cloud для візуалізації. Примітка: Prometheus використовує слово “інтеграції” для позначення програмного забезпечення, яке виставляє метрики Prometheus без необхідності експортера, що по-іншому використовує те саме слово, яке ми використовуємо тут. |
| Graph | Типово використовувана візуалізація, яка відображає дані у вигляді точок, ліній або стовпчиків. | |
| Mixin | Міксин - це набір інформаційних панелей Grafana та правил та сповіщень Prometheus, написаних на Jsonnet та упакованих у комплект. | |
| Panel | Can be moved and resized within a dashboard. Основний будівельний блок у Графані, що складається із запиту (query) та візуалізації. Можна переміщати та змінювати розмір на панелі приладів. | |
| Plugin | Розширення Grafana, яке дозволяє користувачам надавати додаткові функціональні можливості для покращення свого досвіду. Типи підтримуваних плагінів: | |
| App plugin: Розширює Grafana з індивідуальним досвідом. Він включає набір плагінів панелей та джерел даних, а також власні сторінки. | ||
| Data source plugin: Розширює Grafana підтримкою додаткових джерел даних. | ||
| Panel plugin: Розширює Grafana додатковими параметрами візуалізації. | ||
| Query | Запит | Використовується для запиту даних із джерела даних. Структура та формат запиту залежать від конкретного джерела даних. |
| Time series | Часові ряди | Ряди вимірювань, упорядковані за часом. Часові ряди зберігаються у джерелах даних і повертаються в результаті запиту. |
| Trace | Спостерігається шлях виконання запиту через розподілену систему. Для отримання додаткової інформації зверніться до Що таке розподілене відстеження? | |
| Transformation | Трансформації обробляють набір результатів запиту до його надсилання для візуалізації. Для отримання додаткової інформації зверніться до теми Огляд трансформацій. | |
| Visualization | Графічне представлення результатів запиту. |